在 gem5 中启用多 GPU 支持
引言
在过去十年中,GPU 已成为计算密集型、通用 GPU 应用程序(如机器学习、大数据分析和大规模模拟)的重要资源。未来,随着机器学习和大数据的爆炸式增长,应用程序需求将继续增加,导致更多数据和计算被推送到 GPU。然而,由于摩尔定律的放缓以及制造成本的上升,在单个 GPU 设备中添加计算资源以提高其吞吐量变得越来越具有挑战性。因此,在数据中心和科学应用中,将工作分散到多个 GPU 上很流行。例如,Facebook 在其最近的机器学习平台中每台服务器使用 8 个 GPU。
然而,研究基础设施并未跟上这一趋势:大多数 GPU 硬件模拟器,包括 gem5,仅支持单个 GPU。因此,很难研究 GPU 之间的干扰、GPU 之间的通信或跨 GPU 的工作调度。我们的研究小组一直在通过为 gem5 添加多 GPU 支持来解决这一不足。在这篇博客文章中,我们讨论了所需的更改,包括更新仿真驱动程序、GPU 组件和一致性协议。
gem5 AMD APU
最近的 gem5 AMD APU 模型使用在 ROCm(Radeon Open Compute Platform)上执行的准确、高保真 GPU 时序模型扩展了 gem5,ROCm 是 AMD 的 GPU 加速计算框架。图 1 显示了 gem5 模拟 GPU 时的模拟流程。应用程序源代码由 HCC 编译器编译,生成包含 CPU 的 x86 代码和 GPU 的 gcn3 代码的应用程序二进制文件,这些代码被加载到模拟内存中。编译的程序调用 ROCr 运行时库,该库调用 ROCt 用户空间驱动程序。此驱动程序对内核融合驱动程序 (ROCk) 进行 ioctl() 系统调用,由于当前 GPU 支持使用系统调用仿真 (SE) 模式,因此在 gem5 中模拟该驱动程序。
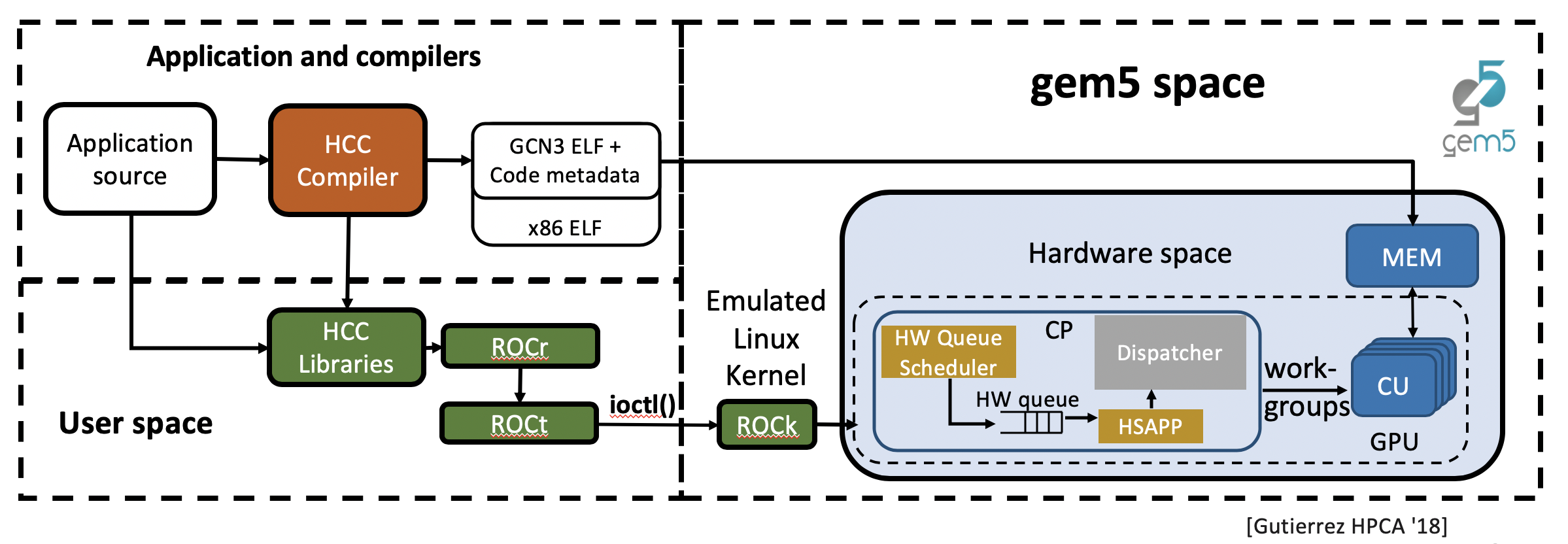
Figure 1. gem5 Simulation Flow
gem5 中的多 GPU 支持
ROCm 框架中的用户空间库和驱动程序已经提供多 GPU 支持。因此,我们发现只需要更新 gem5 的多 GPU 支持。特别是,需要三个主要更改:
- 复制 GPU 组件
- 为多 GPU 添加仿真驱动程序 (ROCk) 支持
- 在 gem5 一致性协议中启用写回支持
复制 GPU 组件
支持多 GPU 的第一步是为每个模拟的 GPU 复制 GPU 硬件组件。图 2 显示了我们复制的 GPU 组件。我们选择在所有 GPU 上使用单个驱动程序,因为所有 GPU 共享单个节点。因此,我们在配置脚本 (apu_se.py) 和拓扑脚本 (hsaTopology.py) 中添加了一个循环,以实例化共享单个仿真驱动程序 (ROCk) 的多个 GPU 节点。每个 GPU 都有自己的命令处理器、硬件调度器、包处理器、调度器和计算单元。为了确保每个 GPU 组件可区分,我们还为每个组件的对象类添加了唯一的 GPU ID 参数。对于在特定地址范围上操作的组件(例如,包处理器),我们还为它们分配了唯一的地址范围以避免重叠。最后,我们通过更改缓存 (GPU_VIPER.py) 和 TLB (GPUTLBConfig.py) 配置脚本来复制缓存和 TLB 层次结构。
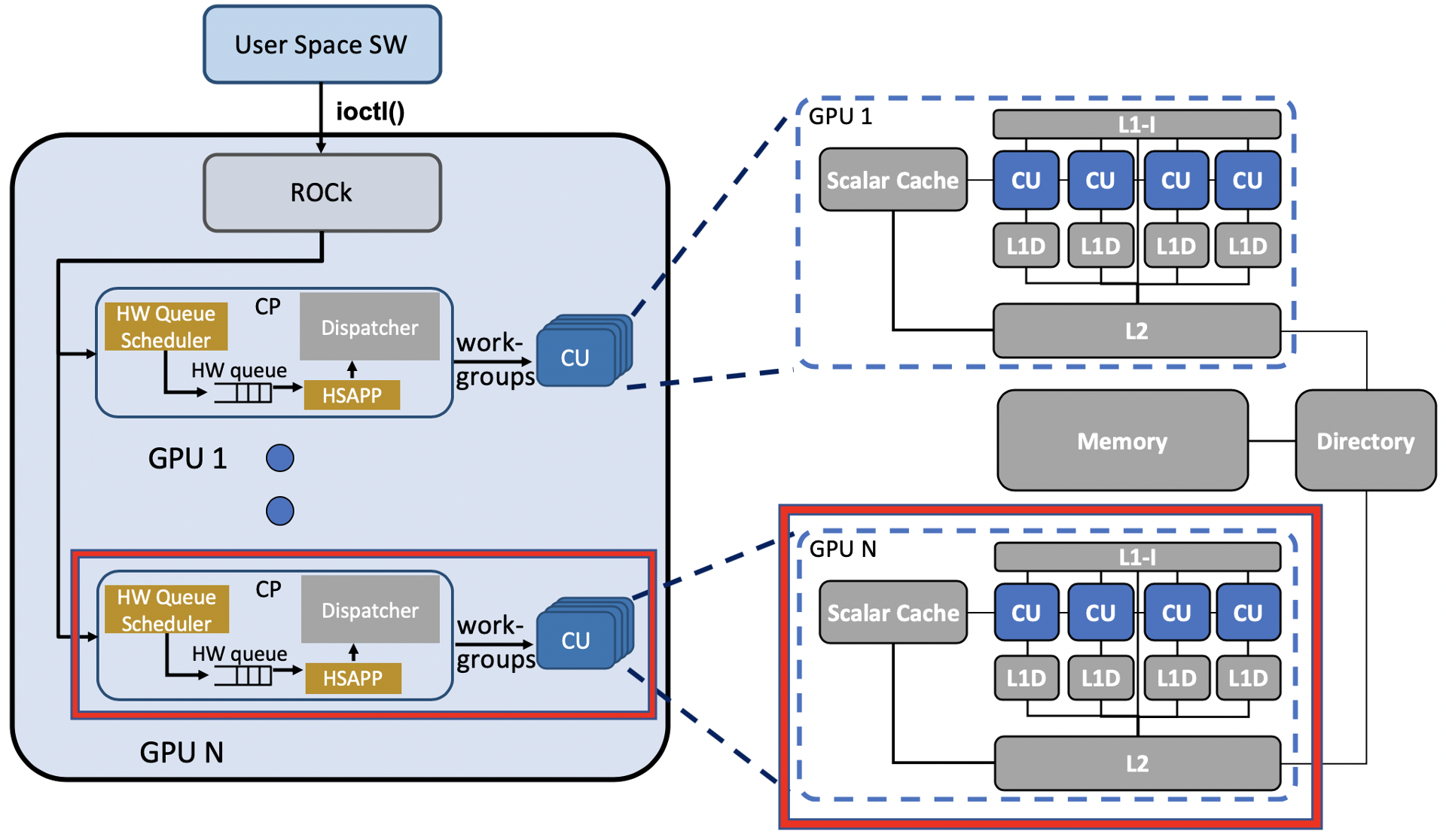
Figure 2. Replicated GPU Components
为多 GPU 添加仿真驱动程序 (ROCk) 支持
由于 gem5 中的仿真 ROCk 仅支持单个 GPU,我们需要为 ROCk 添加多 GPU 支持。这需要两个重大更改:
- 管理软件队列并向多个 GPU 发送工作。
- 将门铃映射到多个 GPU。
管理软件队列并向多个 GPU 发送工作。
应用程序通常通过一个或多个软件队列与 GPU 通信。这些软件队列包含将分配给 GPU 的应用程序内核。图 3 显示了多个应用程序如何通过软件队列与多个 GPU 交互:队列对应用程序是私有的,但应用程序可能有多个队列。由于 gem5 仿真来自 Linux 的 ROCk 内核空间驱动程序,此仿真驱动程序创建和管理软件队列。要创建队列,用户空间代码对 ROCk 进行 ioctl() 系统调用以请求创建队列。ROCk 从 ioctl() 参数获取 GPU ID,并将内核分配给用户指定的适当 GPU。虽然 GPU ID 是创建队列时的参数,但它没有传递给操作队列的例程。因此,当使用多个 GPU 时,为了进一步管理队列,ROCk 必须知道队列服务于哪个 GPU。例如,当程序销毁队列时,ROCk 必须删除 GPU 中指向该队列的共享状态。为了解决这个问题,我们在 ROCk 中添加了一个哈希表来维护队列到 GPU 的映射。因此,仿真 ROCk 驱动程序现在可以简单高效地识别与每个队列关联的 GPU。
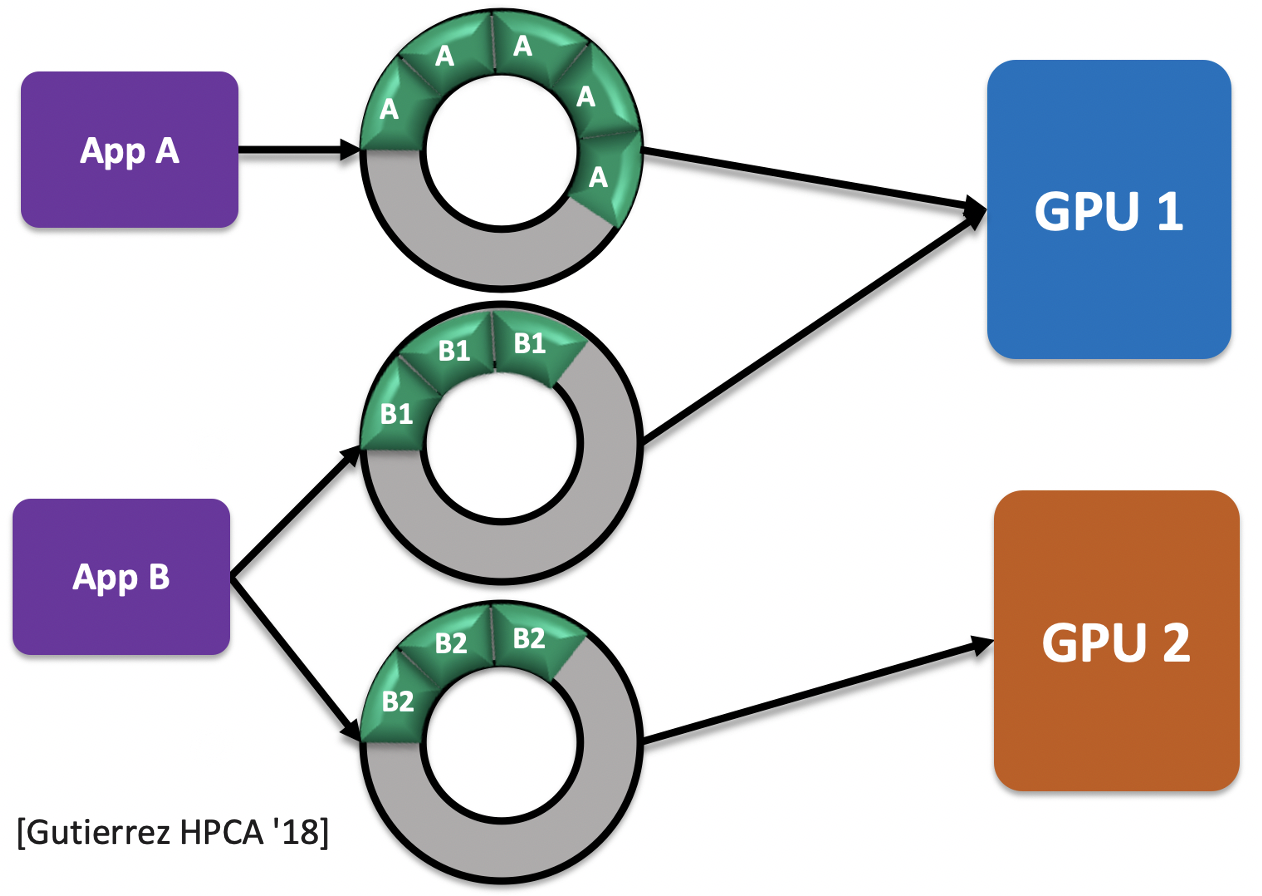
Figure 3. Applications to GPU Communication
将门铃映射到多个 GPU。
GPU 使用门铃作为用户空间软件通知 GPU 有工作要完成的机制。软件将数据放置在相互同意的内存位置,并通过写入门铃区域来”按门铃”。这种”按门铃”的行为通知 GPU 有一些工作准备处理。由于我们使用多个 GPU,我们还需要多个门铃区域,每个 GPU 一个。软件通过使用 mmap() 系统调用将区域映射到虚拟内存来访问门铃区域。
然而,GPU 身份对 mmap() 系统调用不可见,因此仿真 ROCk 驱动程序不知道将哪个 GPU 映射到门铃区域。我们通过将 GPU ID 编码到传递给 mmap() 的 offset 参数中来解决这个问题。编码的偏移量从创建队列 ioctl() 调用返回到用户空间。因此,mmap() 系统调用可以从 offset 参数解码 GPU ID,并识别用于映射的关联 GPU 门铃区域。此机制如图 4 所示。
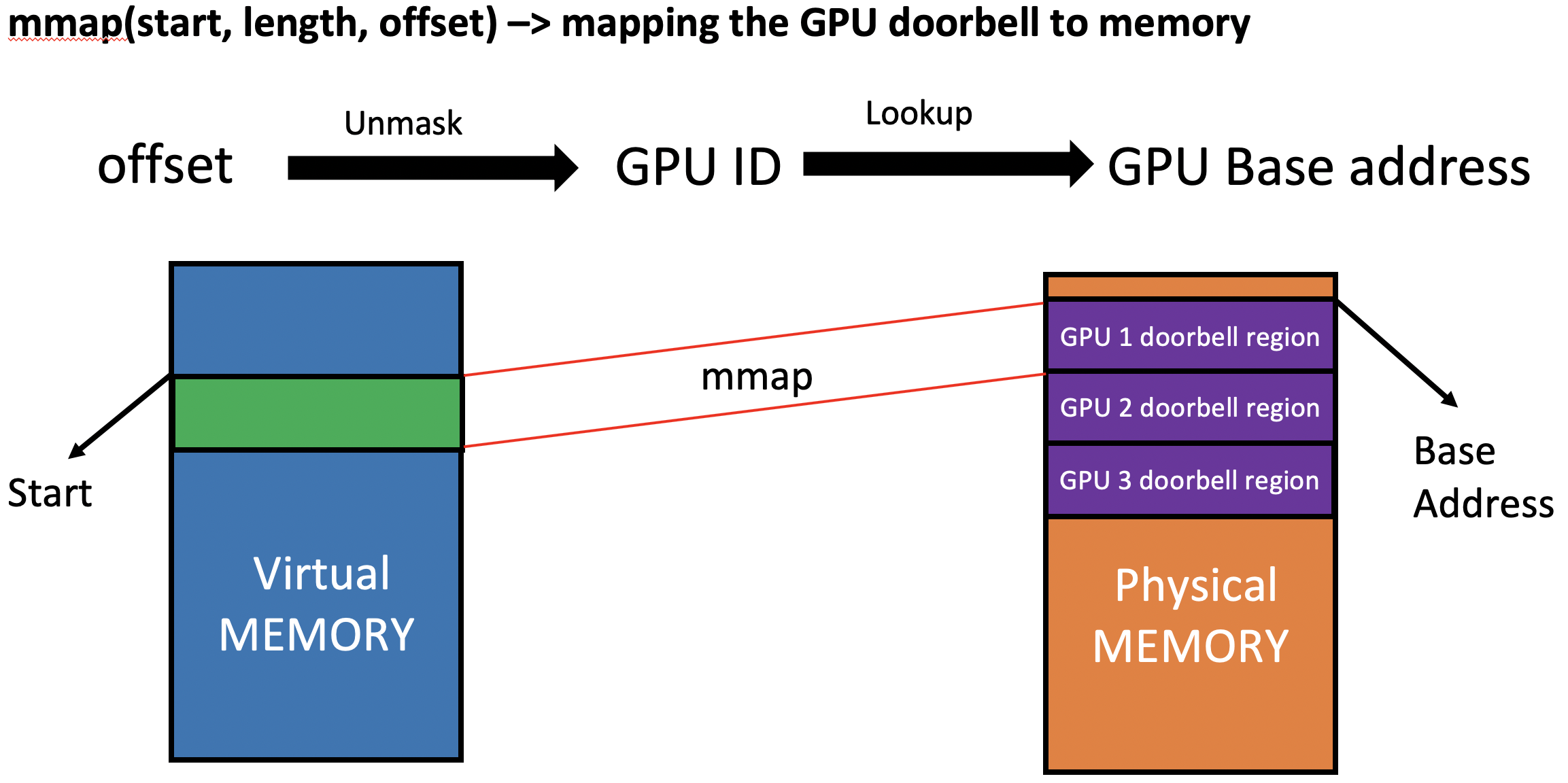
Figure 4. Mapping Doorbell Region for Multiple GPUs
Enabling Writeback Support in gem5 Coherence Protocol
Currently, the gem5 GPU coherence protocol uses a write-through (WT) approach for both L1 and L2 caches. Although this is a valid implementation, in multi-GPU systems it leads to significant bandwidth pressure on the directory and main memory. Moreover, modern AMD and NVIDIA GPUs generally have the GPU’s last-level cache be writeback (WB) caches. Therefore, we decided to change the GPU’s L2 cache in gem5 to be WB instead of WT. Although partial support already existed in gem5 for WB GPU L2 caches, it did not work correctly because the flush operations necessary for correct ordering were not being sent to the L2.
Figure 5 shows how our added GPU WB support compares to the current WT approach. In the WT version, all written data is propagated through the cache hierarchy and therefore is visible to the other cores shortly after the write occurs. However, our WB support holds dirty data in the GPU’s L2 without notifying the directory (step 3). In this situation, the dirty data is not visible nor accessible to the other cores and directory. This is safe because the GPU memory consistency model assumes data race freedom. However, to ensure this dirty data is made visible to other cores by the next synchronization point (e.g., a store release or the end of the kernel), we modified the coherence implementation to forward the flush instructions, generated on store releases and the end of kernels, to the L2 cache (steps 4 and 5), which flushes all dirty L2 entries (step 6). This ensures that all dirty data is visible to the other cores and the directory at the end of every kernel, while also providing additional reuse opportunities and reducing pressure on the directory.
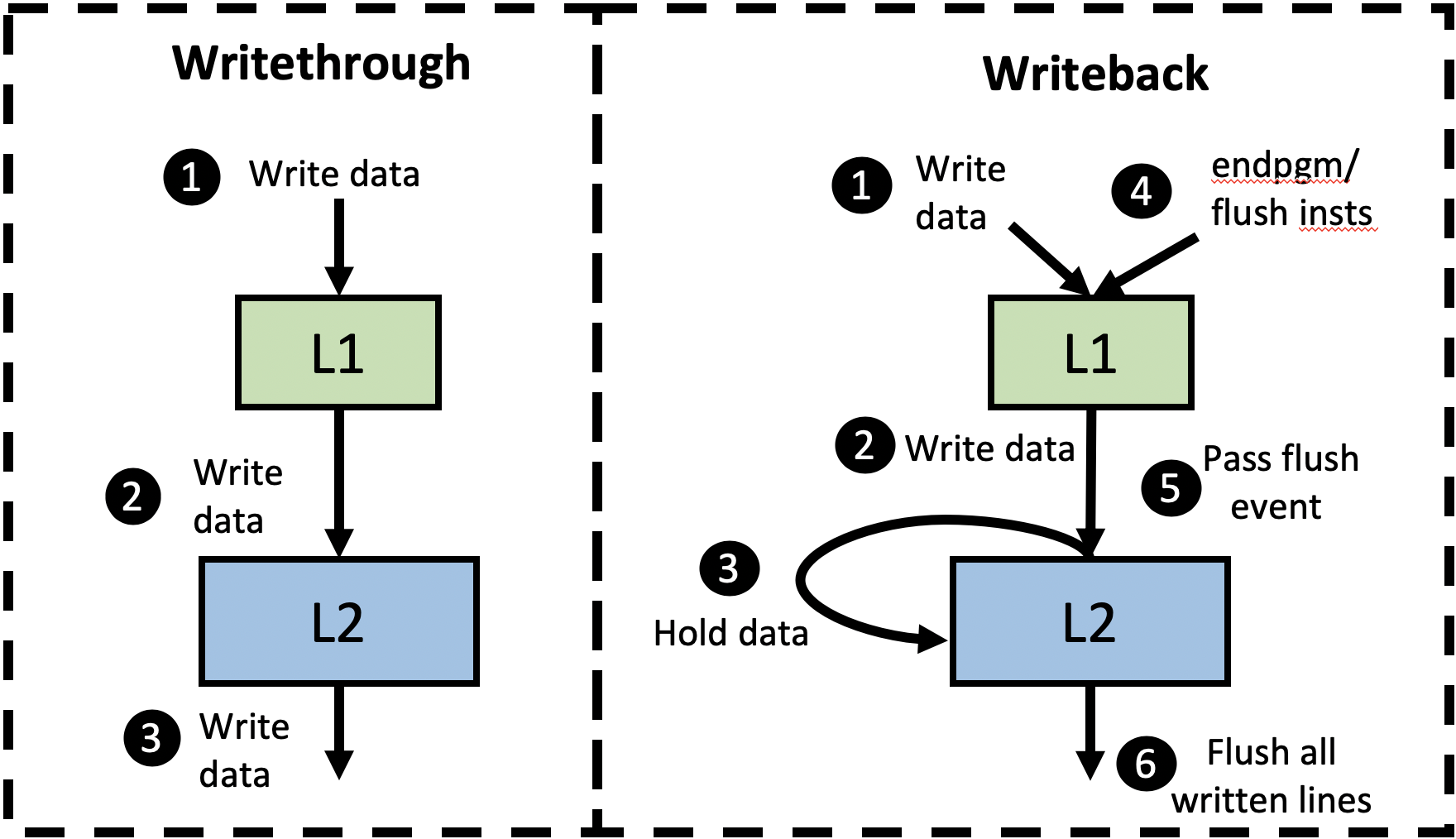
Figure 5. Writethrough vs Writeback Implementation
Conclusion
In the recent few years, multi-GPU systems have become increasingly common as more data and computation being pushed into GPU. However, up until now, gem5 only simulates a single GPU, which makes it difficult to study issues arising in multi-GPU system. Our research group attempts to address this issue by extending multi-GPU support in gem5 by (1) Replicating the GPU components, (2) Modifying the emulated driver, and (3) Enabling writeback support in the coherence protocol.
Workshop Presentation
For additional details about our changes and some experimental results, check out our workshop presentation!
Acknowledgments
This work is supported in part by the National Science Foundation grant ENS-1925485.