gem5 中 Arm 的事务内存扩展支持
This post was originally posted on the Arm Research Blog: here
April 16 2021: The code example in this article has been updated to reflect the Armv9-A architecture release and to be functional with respect to the gem5/ruby model.
向并发的转变
2005 年,Herb Sutter 发表了他的开创性文章”The Free Lunch is Over” (Sutter, 2005)。他概述了微处理器的顺序性能将很快达到平台期,行业将通过增加核心数量来提供更高性能的处理器来应对。这种范式转变的后果是从纯粹的顺序编程模型转向具有多个执行线程的并发模型。当应用程序本质上表现出并行性时,在多个线程之间分配工作可以在线程在不同核心上执行时产生性能提升。
多线程并发有两个主要缺点——(1) 同步的开销,例如锁的序列化性质,以及 (2) 编程、调试和验证的困难。在描述不同同步策略时,这两个属性之间通常存在反相关关系,例如粗粒度锁定、细粒度锁定和无锁算法。
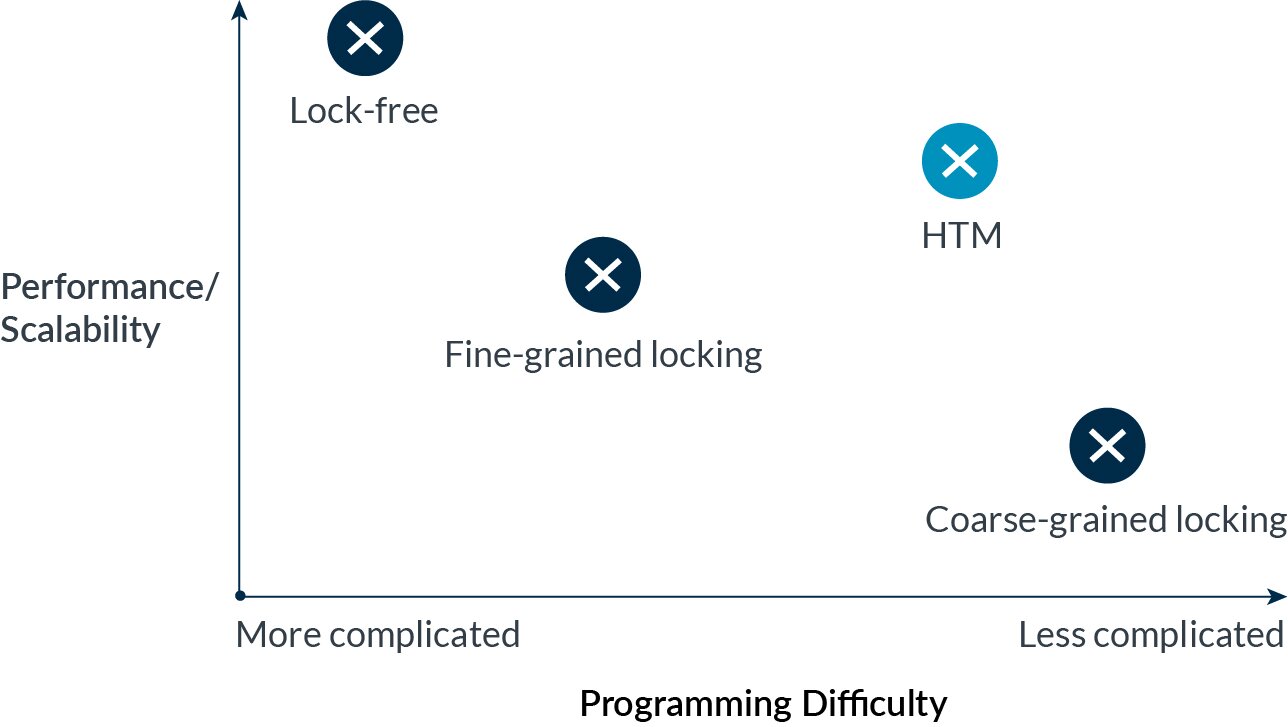
图 1:实现更高性能/可扩展的并发通常以增加难度为代价。
硬件事务内存 (HTM) 允许两个或多个线程在不使用互斥锁等序列化原语的情况下并行安全地执行临界区(即事务)。事务以原子性、一致性和隔离性 (Harris, et al., 2007) 的属性推测性地执行,微架构负责检测和从竞争条件中恢复。例如,如果一个线程写入另一个线程已读取的内存位置。这可以在更简单的编程模型下提供增加的并行性。
Arm 的 TME
事务内存扩展 (TME) 是 Armv9 的可选功能(以前是 Arm 的 A-profile 未来架构技术计划的一部分)。TME 是一种尽力而为的 HTM 架构,不保证事务的完成。程序员必须提供回退路径以保证进度,例如互斥锁保护的临界区。它提供强隔离,意味着事务与其他事务以及并发的非事务内存访问隔离。它使用扁平化的事务嵌套,其中嵌套事务被外部事务包含。嵌套事务的效果在外部事务提交之前对其他观察者不可见。当嵌套事务中止时,它会导致外部事务(及其内部的所有嵌套事务)中止。
TME 包含四条指令:
-
TSTART <Xd> - 此指令启动新事务。如果事务成功启动,目标寄存器设置为零,处理器进入事务状态。如果事务失败或被取消,则所有以事务方式执行的状态修改都将被丢弃。然后目标寄存器被写入一个非零值,该值编码失败的原因。
-
TCOMMIT - 此指令提交当前事务。如果当前事务是外部事务,则退出事务状态,并且所有以事务方式执行的状态修改都提交到架构状态。
-
TCANCEL #<imm> - 此指令退出事务状态并丢弃所有以事务方式执行的状态修改。执行在外部事务的
TSTART指令之后的指令处继续。外部事务的TSTART指令的目标寄存器被写入TCANCEL的立即操作数。 -
TTEST <Xd> - 此指令将事务的深度写入目标寄存器,否则写入值 0。
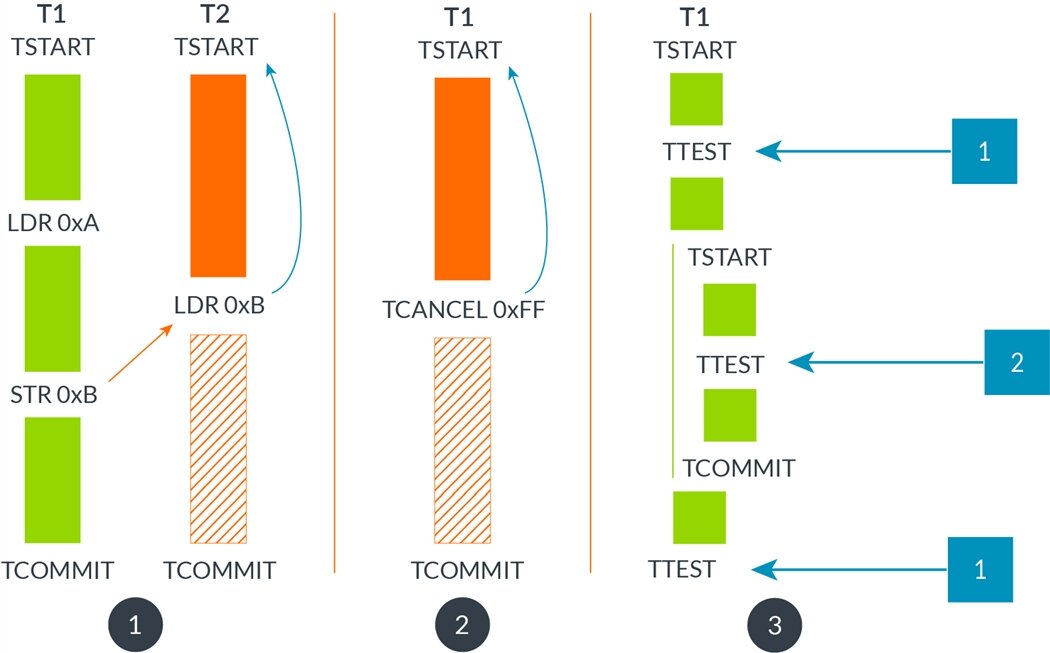
图 2:说明了四条 TME 指令的语义。(1) 显示两个线程创建和提交事务。线程 T1 与线程 T2 冲突,因此 T2 中止其事务并回滚到 TSTART 指令。T2 的 TCOMMIT 永远不会到达。(2) 线程 T1 创建事务但使用 TCANCEL 手动中止它。它中止并回滚到 TSTART。T1 的 TCOMMIT 永远不会到达。(3) 线程 T1 创建并提交嵌套事务,其中测试事务深度。当 TTEST 在外部事务中执行时返回 1,而如果它在内部事务中执行则返回 2。
在 gem5 中建模 TME
gem5 是一个开源系统和处理器模拟器,广泛用于学术界和工业界的计算机体系结构研究。gem5 提供两种替代内存系统——经典和 Ruby。经典内存系统继承自 gem5 的前身 M5,并实现了 MOESI 一致性协议 (Sorin, Hill, & Wood, 2011)。相比之下,Ruby 内存系统提供了一种定义和模拟自定义缓存一致性协议的灵活方法,包括一系列互连和拓扑。协议通过使用领域特定语言 SLICC(包括缓存一致性的规范语言)的状态、转换、事件和操作来指定。gem5 包括各种默认可用的 Ruby 缓存一致性协议,但是,这些协议目前都不支持 HTM。
HTM 可以通过多种方式实现,具有不同的权衡。为了原型化 Arm 的 TME,我们选择了一种在微架构中实现 ISA 扩展的特定方式。简而言之,它使用延迟版本管理和急切冲突检测,具有缓存行粒度 (Bobba, et al., 2007)。其他实现是可能的,gem5 设计的选择不一定反映任何硅实现——现有的或未来的。
TME 要求实现必须:
- 检查点和恢复架构寄存器状态。
- 跟踪以事务方式读取和写入的状态。
- 缓冲推测性内存更新。
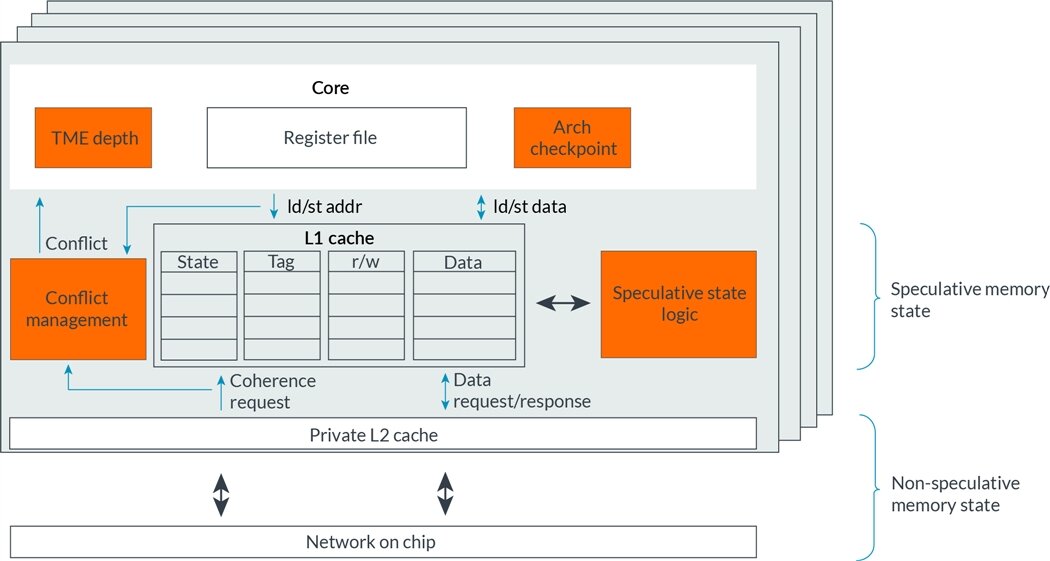
图 3:以橙色突出显示的框是微架构中已添加或修改以支持 TME 的组件。
有几种技术可用于寄存器检查点,包括影子寄存器文件和冻结物理寄存器。在 gem5 中,我们选择了一个功能正确且无开销的检查点机制,即整个寄存器文件的零周期瞬时备份。这允许我们在核心模型之间共享通用检查点机制。
为了将 HTM 支持与 TME 特定功能分离,在 src/arch/ 目录中添加了用于检查点创建和恢复的通用接口。ISA 可以根据其特定需求实现此接口,允许共享和重用大部分 HTM 功能。TME 实现还必须能够在事务失败或取消时回滚架构状态并丢弃推测性更新。这是通过重新利用 gem5 的异常机制来实现的。
为了跟踪事务的读/写集并缓冲推测性内存更新,我们利用缓存一致性协议。gem5 包括 Ruby 协议 MESI_Three_Level。MESI 指的是缓存行可以处于的状态:Modified(修改)、Exclusive(独占)、Shared(共享)或 Invalid(无效)(Sorin, Hill, & Wood, 2011)。该协议利用由更大的统一包含私有 L2 缓存提供的私有 L1 数据和指令缓存。L2 缓存由更大的包含共享 L3 缓存和一致性目录支持。
MESI_Three_Level 协议已增强以支持 TME。L1 数据缓存用于缓冲与系统其余部分隔离的推测状态。因为 L2 缓存是包含的,它包含事务读/写集中使用的相同行,但保存它们的预事务值。此配置的后果是事务的工作集必须仅驻留在 L1 数据缓存中。如果以事务方式读取或写入的行溢出,即从 L1 数据缓存逐出到 L2 缓存,则事务必须中止,并且必须丢弃任何推测性写入的数据。
为了跟踪以事务方式读取和写入的状态,在每个 L1 数据缓存行的标签中添加了两个额外的”位”——如果它在事务的读集中则为 1 位,如果它在写集中则为另一位。这些位在从一个缓存行状态转换到另一个状态时使用。要提交事务,两个位都被清除。要中止事务,如果行既是修改的又在事务的写集中,则行转换到无效;类似于提交,两个位也被清除。我们假设这些位可以原子地清除,以便对外部观察者来说,要么所有事务状态提交(变为非推测性),要么被丢弃并回滚。这满足了事务内存的原子性属性。
示例程序
为了测试 gem5 中的新功能,我们概述了一个用 C 编写的简单程序,该程序使用 TME 事务并行更新直方图。此程序使用手动锁消除——使用锁来保护共享数据结构,但尽可能绕过(即消除)它,转而使用事务。这满足如果事务无法取得进展则回退路径的要求。
我们首先定义一个非常简单的自旋锁,它适用于 AArch64 的弱内存模型和 TME。Arm 推荐的使用 Load-Exclusive/Store-Exclusive 的锁获取序列通常依赖于加载获取独占指令(例如 LDAXR)以进行正确的内存排序。当这种形式的锁获取与 TME 锁消除一起使用时,无法保证互斥。为了规避这个问题,有两种可能的解决方案:
- 使用 Armv8.1 大型系统扩展 (LSE) 原子操作构建锁获取序列。这是可以在 Linux 内核中找到的习惯性和高性能 Armv8-A 和 Armv9-A 锁序列。
- 在临界区的第一个内存操作之前添加完整的内存屏障 (DMB SY)。
由于 LSE 原子操作目前在 gem5/ruby 中未实现,我们使用第二个选项。
#include <stdatomic.h>
typedef atomic_int lock_t;
inline void lock_init(lock_t *lock) {
atomic_init(lock, 0);
}
inline void lock_acquire(lock_t *lock) {
// The following atomic exchange can use relaxed memory
// ordering since it is followed by a full barrier.
while (atomic_exchange_explicit(lock, 1, memory_order_relaxed))
; // spin until acquired
// This will generate a full memory barrier, e.g. DMB SY
atomic_thread_fence(memory_order_seq_cst);
}
inline int lock_is_acquired(lock_t *lock) {
return atomic_load_explicit(lock, memory_order_acquire);
}
inline void lock_release(lock_t *lock) {
atomic_store_explicit(lock, 0, memory_order_release);
}
接下来,我们编写一个函数来使用 TME 事务消除锁。lock_acquire_elided 如果锁成功消除则返回 1,否则返回 0。该函数启动新事务并检查锁是否仍然空闲,因此将其添加到事务的读集中。如果锁不空闲,则通过 TCANCEL 显式中止事务。在我们的示例中,作为参数传递的特定 15 位整数并不重要,但是,设置 MSB 确保可以重试事务。
#include <arm_acle.h>
#define TME_MAX_RETRIES 3
#define TME_LOCK_IS_ACQUIRED 65535
int lock_acquire_elided(lock_t *lock) {
int num_retries = 0;
uint64_t status;
do {
status = __tstart();
if (status == 0) {
// check if lock is acquired and add it to our read-set
if (lock_is_acquired(lock)) {
__tcancel(TME_LOCK_IS_ACQUIRED);
__builtin_unreachable();
}
return 1;
}
++num_retries;
} while ((status & _TMFAILURE_RTRY) && (num_retries < TME_MAX_RETRIES));
// the transaction failed too many times
return 0;
}
void lock_release_elided() {
__tcommit();
}
然后利用这些自旋锁和事务例程创建函数 work,该函数更新堆上的全局共享数组结构。此函数可以从多个线程并行调用。
#include <stdio.h>
#include <stdlib.h>
#include "lock.h"
#define ARRAYSIZE 512
#define ITERATIONS 10000
volatile long int histogram[ARRAYSIZE];
lock_t global_lock;
void* work(void* void_ptr) {
// Use thread id for RNG seed,
// this will prevent threads generating the same array indices.
long int idx = (long int)void_ptr;
unsigned int seedp = (unsigned int)idx;
int i, rc;
printf("Hello from thread %ld\n", idx);
for (i=0; i<ITERATIONS; i++)
{
int num1 = rand_r(&seedp)%ARRAYSIZE;
rc = lock_acquire_elided(&global_lock);
if (rc == 0) // eliding the lock failed
lock_acquire(&global_lock);
// start critical section
long int temp = histogram[num1];
temp += 1;
histogram[num1] = temp;
// end critical section
if (rc == 1)
lock_release_elided();
else
lock_release(&global_lock);
}
printf("Goodbye from thread %ld\n", idx);
}
最后,我们使用生成和连接工作线程的 main 函数将所有内容组合在一起。
#include <assert.h>
#include <pthread.h>
#include <unistd.h>
int main() {
long int i, total, numberOfProcessors;
pthread_t *threads;
int rc;
numberOfProcessors = sysconf(_SC_NPROCESSORS_ONLN);
printf("TME parallel histogram with %ld procs\n", numberOfProcessors);
lock_init(&global_lock);
// initialise the array
for (i=0; i<ARRAYSIZE; i++)
histogram[i] = 0;
// spawn work
threads = (pthread_t*) malloc(sizeof(pthread_t)*numberOfProcessors);
for (i=0; i<numberOfProcessors-1; i++) {
rc = pthread_create(&threads[i], NULL, work, (void*)i);
assert(rc==0);
}
work((void*)(numberOfProcessors-1));
// wait for worker threads
for (i=0; i<numberOfProcessors-1; i++) {
rc = pthread_join(threads[i], NULL);
assert(rc==0);
}
// verify array contents
total = 0;
for (i=0; i<ARRAYSIZE; i++)
total += histogram[i];
// free resources
free(threads);
printf("Total is %lu\nExpected total is %lu\n",
total, ITERATIONS*numberOfProcessors);
return 0;
}
编译和运行
TME 在 GCC 版本 10 中受支持——这包括 ACLE 内联函数。要编译包含 TME 指令的源文件,必须使用 AArch64 编译器,并通过 march 标志启用该功能,例如 -march=armv8-a+tme。
aarch64-linux-gnu-gcc -std=c11 -O2 -static -march=armv8-a+tme+nolse -pthread -o histogram.exe ./histogram.c
截至本文撰写时,gem5 在经典内存系统中实现了 Arm 的大型系统扩展 (LSE),但 Ruby 中没有。为了轻松使用系统仿真模式,应在源代码树中禁用此功能。要在 gem5 v20.1 中执行此操作,请修改 ./src/arch/arm/isa.cc:l106 并将 haveLSE 从 true 更改为 false。
然后必须使用新的 Ruby MESI_Three_Level_HTM 协议编译 gem5。
scons CC=gcc CXX=g++ build/ARM_MESI_Three_Level_HTM/gem5.opt TARGET_ISA=arm PROTOCOL=MESI_Three_Level_HTM SLICC_HTML=True CPU_MODELS=AtomicSimpleCPU,TimingSimpleCPU,O3CPU -j 4
在系统仿真模式下运行直方图可执行文件
./gem5/build/ARM_MESI_Three_Level_HTM/gem5.opt ./gem5/configs/example/se.py --ruby --num-cpus=2 --cpu-type=TimingSimpleCPU --cmd=./blogexample/histogram.exe
输出应该类似于:
TME parallel histogram with 2 procs
Hello from thread 1
Hello from thread 0
Goodbye from thread 1
Goodbye from thread 0
Total is 20000
Expected total is 20000
Exiting @ tick 718668000 because exiting with last active thread context
为了验证是否有任何临界区以事务方式执行,我们检查 m5out/stats.txt,其中包含几个与 HTM 相关的统计信息。
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::explicit 35 22.01% 22.01% # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::transaction_size 38 23.90% 45.91% # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::memory_conflict 86 54.09% 100.00% # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::total 159 # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::samples 9927 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::mean 63.466103 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::gmean 56.438036 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::stdev 29.029108 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::32-47 4854 48.90% 48.90% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::48-63 2 0.02% 48.92% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::64-79 195 1.96% 50.88% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::80-95 4627 46.61% 97.49% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::96-111 188 1.89% 99.39% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::112-127 60 0.60% 99.99% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::128-143 1 0.01% 100.00% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::total 9927 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::samples 9927 # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::mean 12 # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::gmean 12.000000 # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::12-13 9927 100.00% 100.00% # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::total 9927 # number of instructions spent in an outer transaction
这些是按核心的统计信息,提供有关事务长度(以周期数或指令数)以及中止事务原因的信息。当使用 TCANCEL 时,explicit 递增——在我们的示例代码中,当事务已经开始后观察到全局锁被占用时会发生这种情况。memory_conflict 发生在另一个处理元素尝试修改事务读集或写集中的缓存行时。transaction_size 表示事务溢出 L1 数据缓存;由于这很难准确跟踪,统计信息改为捕获由于源自同一核心的加载/存储而从 L1 数据缓存中逐出的事务缓存行。由于缓存集替换策略等因素,此统计信息经常出现误报。
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::samples 159 # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::mean 0.729560 # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::stdev 0.591988 # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::0 55 34.59% 34.59% # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::1 92 57.86% 92.45% # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::2 12 7.55% 100.00% # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::total 159 # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::samples 159 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::mean 0.169811 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::stdev 0.376653 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::0 132 83.02% 83.02% # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::1 27 16.98% 100.00% # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::total 159 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::samples 9927 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::mean 1.987710 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::gmean 1.983035 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::stdev 0.110181 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::1 122 1.23% 1.23% # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::2 9805 98.77% 100.00% # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::total 9927 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::samples 9927 # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::mean 1 # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::gmean 1 # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::1 9927 100.00% 100.00% # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::total 9927 # write set size of a committed transaction
这些是采样的直方图,包含以使用的缓存行数表示的事务大小。可以观察到,大多数成功的事务从两个唯一的缓存行读取并写入一个。这些是在描述启用 TME 的应用程序时有用的指标。
现已可用
Arm 致力于与开源软件社区合作,并将它实现的创新视为其生态系统持续成功的关键。Arm 在 gem5 中的 TME 支持已经开源并上游化;从 v20.1 开始可用。这为我们的商业和学术合作伙伴提供了许多有用的用例,一些示例包括:
- 在通用硅可用之前测试和基准测试启用 TME 的二进制文件
- 敏感性分析以确定不同的微架构参数如何影响 TME 实现的功效
- 作为研究平台来发现和展示这项技术如何发展。
这项工作是与 Cray 合作完成的,部分由 DOE ECP PathForward 计划 资助。代码基于 Pradip Vallathol 之前的拉取请求,他在 gem5 中开发了 HTM 和 TSX 支持,作为其硕士论文的一部分。作者要感谢所有内部和外部代码审查者。
引用文献
Bobba, J., Moore, K. E., Volos, H., Yen, L., Hill, M. D., Swift, M. M., & Wood, D. A. (2007). Performance pathologies in hardware transactional memory. ACM SIGARCH Computer Architecture News, 35(2), 81-91.
Harris, T., Cristal, A., Unsal, O. S., Ayguade, E., Gagliardi, F., Smith, B., & Valero, M. (2007, August 20). Transactional Memory: An Overview. IEEE Micro, 27(3), pp. 8-29.
Sorin, D. J., Hill, M. D., & Wood, D. A. (2011). A Primer on Memory Consistency and Cache Coherence. Synthesis lectures on computer architecture, 6(3), 1-212.
Sutter, H. (2005). The free lunch is over: A fundamental turn toward concurrency in software. Dr. Dobb’s journal, 30(3), 202-210.