
执行基础
gem5 bootcamp 2022 关于指令执行的模块
gem5 bootcamp (2022) 有一个关于学习指令如何在 gem5 中工作以及如何在 gem5 中添加新指令的会议。 会议中展示的幻灯片可以在 这里 找到。
录制的关于 gem5 指令的 bootcamp 模块的 youtube 视频可在 这里 获得。
StaticInsts
StaticInst 提供二进制指令的所有静态信息和方法。
它保存以下信息/方法:
- 标志,告知它是什么类型的指令(整数、浮点、分支、内存屏障等)
- 指令的操作类
- 源和目标寄存器的数量
- 使用的整数和 FP 寄存器的数量
- 将二进制指令解码为 StaticInst 的方法
- 虚函数 execute(),定义了针对指令采取的具体架构操作(例如读取 r1, r2,将它们相加并存储在 r3 中。)
- 处理开始和完成内存操作的虚函数
- 对于将内存操作分为两个操作的模型,分别执行地址计算和内存访问的虚函数
- 反汇编指令的方法,以人类可读的格式打印出来。(例如 addq r1 r2 r3)
它没有动态信息,例如指令的 PC 或源寄存器的值或结果。这允许将 StaticInst 1 对 1 映射到唯一的二进制机器指令。我们利用这一事实,将二进制指令到 StaticInst 的映射缓存在 hash_map 中,允许我们仅解码一次二进制指令,并在其余时间直接使用 StaticInst。
每个 ISA 指令都派生自 StaticInst 并实现其自己的构造函数、execute() 函数,如果是内存指令,则实现内存访问函数。有关如何指定这些 ISA 指令的详细信息,请参见 ISA_description_system。
DynInsts
DynInst 用于保存有关指令的动态信息。这对于更详细的模型或乱序模型是必需的,两者都可能需要超出 StaticInsts 的额外信息才能正确执行指令。 它存储的一些动态信息包括:
- 指令的 PC
- 源和目标寄存器的重命名寄存器索引
- 预测的下一条 PC
- 指令结果
- 指令的线程号
- 指令正在执行的 CPU
- 指令是否被挤压
此外,DynInst 还提供 ExecContext 接口。当执行 ISA 指令时,DynInst 作为 ExecContext 传入,处理 ISA 对 CPU 状态的所有访问。
详细的 CPU 模型可以从 DynInst 派生并创建自己的特定 DynInst 子类,以实现可能需要的任何其他状态或函数。有关示例,请参见 src/cpu/o3/alpha/dyn_inst.hh。
微码支持
ExecContext
ExecContext 描述了 ISA 用于访问 CPU 状态的接口。虽然有一个文件 src/cpu/exec_context.hh,但它纯粹用于文档目的,类不从它派生。相反,ExecContext 是 ISA 假定的隐式接口。
ExecContext 接口提供以下方法:
- 读取和写入 PC 信息
- 读取和写入整数、浮点和控制寄存器
- 读取和写入内存
- 记录并返回内存访问的地址、预取和触发系统调用
- 触发一些全系统模式功能
ExecContext 接口的示例实现包括:
- SimpleCPU
- DynInst
有关如何实现指令集的更多详细信息,请参见 ISA 描述页面。
ThreadContext
ThreadContext 是针对 CPU 外部任何事物的线程所有状态的接口。它提供了读取或写入外部对象可能需要的状态的方法,例如 PC、下一条 PC、整数和 FP 寄存器以及 IPR。它还提供了获取指向重要线程相关类的指针的函数,例如 ITB、DTB、System、内核统计信息和内存端口。它是一个抽象基类;CPU 必须通过派生自它或使用模板化的 ProxyThreadContext 类来创建自己的 ThreadContext。
ProxyThreadContext
ProxyThreadContext 类提供了一种无需派生即可实现 ThreadContext 的方法。ThreadContext 是一个抽象类,因此任何从它派生并使用其接口的东西都将支付虚函数调用的开销。创建此类是为了使用户定义的 Thread 对象可以在使用 ThreadContexts 的任何地方使用,而在单独使用时无需支付虚函数调用的开销。用户定义的对象必须简单地提供与普通 ThreadContext 相同的所有函数,并且 ProxyThreadContext 将把所有调用转发给用户定义的对象。有关使用 ProxyThreadContext 的示例,请参见 SimpleThread 的代码。
与 ExecContext 的区别
ThreadContext 与 ExecContext 略有不同。ThreadContext 提供对单个线程状态的访问;ExecContext 提供 ISA 对 CPU 的访问(意味着它在 SMT 系统上隐式多线程)。此外,ThreadState 是一个精确定义接口的抽象类;ExecContext 是一个更隐式的接口,必须实现它以便 ISA 可以访问它需要的任何状态。访问状态的函数调用在两者之间略有不同。ThreadContext 提供读取/写入寄存器方法,这些方法接受架构寄存器索引。ExecContext 提供读取/写入寄存器方法,这些方法接受 StaticInst 和索引,其中索引指的是该 StaticInsts 的第 i 个源或目标寄存器。此外,ExecContext 提供读取和写入方法来访问内存,而 ThreadContext 不提供任何访问内存的方法。
ThreadState
ThreadState 类用于保存 CPU 模型通用的线程状态,例如线程 ID、线程状态、内核统计信息、内存端口指针以及已完成指令数的统计信息。每个 CPU 模型都可以从 ThreadState 派生并以此为基础,添加被认为合适的线程状态。这方面的一个例子是 SimpleThread,其中添加了所有线程的架构状态。但是,没有必要(甚至在某些情况下不可行)将所有线程状态集中在 ThreadState 派生类中。DetailedCPU 将寄存器值和重命名映射保存在 ThreadState 之外的自己的类中。ThreadState 仅用于提供一种更方便的方式来集中定位某些状态,并在 CPU 模型之间提供共享。
故障
寄存器
寄存器类型 - float, int, misc
索引 - 寄存器空间内容
有关更透彻的处理,请参见 Register Indexing。
CPU 模型中扁平化和寄存器索引的“五分钱之旅”。
首先,指令已确定它需要寄存器某某,这是由其编码确定的(或者它总是使用某个寄存器这一事实,或者…)。为了便于讨论,假设我们正在谈论 SPARC,寄存器是 %g1,并且第二组全局变量处于活动状态。从指令的角度来看,未扁平化的寄存器是 %g1,这很可能仅由索引 1 表示。
接下来,我们需要从指令的寄存器文件视图映射到实际的存储位置。这就像虚拟内存。指令在索引空间内工作,就像虚拟地址空间一样,需要将其映射到像物理内存一样的扁平空间。在这里,索引 1 可能映射到,比如,9,其中 0-7 是第一组全局变量,8-15 是第二组。
这是 CPU 介入的地方。索引 9 指的是指令期望访问的实际寄存器,CPU 的工作就是实现这一点。在此之前,所有工作都是由 ISA 完成的,CPU 无法洞察,而在这一点之后,所有工作都由 CPU 完成,ISA 无法洞察。
CPU 可以像简单 CPU 一样通过拥有一个数组并代表指令读取和写入第 9 个元素来直接提供寄存器。或者,CPU 可以做一些复杂的事情,比如像 O3 一样将扁平化索引重命名并映射到物理寄存器。
所有这一切的一个重要属性是,如果您考虑虚拟内存类比,这是有道理的,即扁平化之前的索引空间大小与之后的空间大小无关。虚拟内存空间可能非常大(可能有间隙)并映射到较小的物理空间,或者它可能很小并映射到较大的物理空间,其中额外的空间用于,比如,其他时间使用的其他虚拟空间。您需要确保使用正确的大小(扁平化后)来调整表的大小,因为那是可能选项的空间。
另一个棘手的部分来自我们向索引添加偏移量以区分 int、float 和 misc 的事实。这些偏移量在预扁平化世界中可能是一回事,但在后扁平化世界中需要是另一回事,以防止事物落在彼此之上而不留下间隙。这里很容易出错,这也是我不喜欢这种偏移想法作为区分不同类型的方法的原因之一。我更愿意看到一个二维索引,其中第二个坐标是寄存器类型。但在今天存在的世界里,这是你必须跟踪的事情。
PCs
寄存器索引
gem5 中的 CPU 寄存器索引因需要支持具有有时非常不同的寄存器语义(寄存器窗口、条件代码、基于模式的备用寄存器集等)的多种 ISA 而变得复杂。此外,随着新 ISA 的添加,这种支持逐渐发展,因此旧代码可能无法利用新功能或术语。
寄存器索引的类型
CPU 模型内部使用了三种类型的寄存器索引:相对、统一和扁平化。
相对 (Relative)
相对寄存器索引是机器指令中编码的索引。每类寄存器(整数、浮点等)都有一个单独的索引空间,从 0 开始。寄存器类由操作码暗示。因此,源寄存器字段中的值“1”可能意味着整数寄存器 1(例如,“%r1”)或浮点寄存器 1(例如,“%f1”),具体取决于指令的类型。
统一 (Unified)
虽然相对寄存器索引对于保持指令编码紧凑很有好处,但它们是模棱两可的,因此不便于管理依赖关系等事情。为了避免这种歧义,解码器通过添加特定于类的偏移量将相对寄存器索引映射到统一的寄存器空间,从而将每个相对索引范围重新定位到唯一位置。整数寄存器未修改,并继续从零开始。浮点寄存器索引偏移(至少)整数寄存器的数量,以便第一个 FP 寄存器(例如,“%f0”)获得大于最后一个整数寄存器的统一索引。同样,杂项(又名控制)寄存器被映射到 FP 寄存器索引空间的末尾之后。
扁平化 (Flattened)
统一寄存器索引提供了在执行的给定点可作为指令操作数访问的所有寄存器的明确描述。不幸的是,由于某些 ISA 的复杂特性,它们并不总是明确地标识指令引用的实际状态。例如,在具有寄存器窗口的 ISA(特别是 SPARC)中,特定的寄存器标识符(如 “%o0”)在 “save” 或 “restore” 操作之后将引用与之前不同的寄存器。一些 ISA 有在正常操作中隐藏的寄存器,但在发生中断时(例如,ARM 的特定模式寄存器)或在显式管理程序控制下(例如,SPARC 的“备用全局变量”)映射到普通寄存器之上。
我们通过维护一个扁平化寄存器空间来解决这个问题,该空间为每个唯一的寄存器存储位置提供不同的索引。例如,SPARC 扁平化寄存器空间的整数部分具有针对全局变量和备用全局变量以及每个可用寄存器窗口的不同索引。从统一或相对寄存器索引转换为扁平化寄存器索引的“扁平化”过程因 ISA 而异。在某些 ISA 上,映射是微不足道的,而其他 ISA 使用表查找来进行转换。
生成统一和扁平化寄存器索引的一个关键区别是,前者总是可以静态完成,而后者通常取决于动态处理器状态。也就是说,从相对索引到统一索引的转换仅取决于指令本身提供的上下文(这很方便,因为转换是在解码器中完成的)。相反,到扁平化寄存器索引的映射可能取决于处理器状态,例如中断级别或 SPARC 上的当前窗口指针。
组合寄存器索引类型
虽然修改寄存器索引的典型过程是相对 -> 统一 -> 扁平化,但事实证明,相对与统一以及扁平化与未扁平化是正交属性。相对与统一指示索引是相对于其寄存器类(整数、FP 或 misc)的基址寄存器还是添加了其类的基址偏移量。扁平化与未扁平化指示索引是否已调整以考虑运行时上下文,例如寄存器窗口调整或备用寄存器文件模式。因此,相对扁平化寄存器索引是一种已考虑运行时上下文的索引,但仍相对于其类的基址偏移量表示。
无论索引是扁平化还是未扁平化,都使用一组特定于类的偏移量从相对索引生成统一索引。因此,即使使用扁平化地址,偏移量也必须足够大以分隔寄存器类。结果,未扁平化的统一寄存器空间通常是不连续的。
插图
作为说明,考虑具有四个整数寄存器 (%r0-%r4)、三个 FP 寄存器 (%f0-%f2) 和两个 misc/控制寄存器 (%msr0-%msr1) 的假设架构。此外,该架构支持一套完整的备用整数和 FP 寄存器,用于快速上下文切换。
结果寄存器文件布局以及统一扁平化寄存器文件索引显示在右侧。虽然图片中的索引范围从 0 到 15,但有效索引的实际集合取决于索引的类型以及(对于相对索引)寄存器类:
| 相对未扁平化 | Int: 0-3; FP: 0-2; Misc: 0-1 |
| 统一未扁平化 | 0-3, 8-10, 14-15 |
| 相对扁平化 | Int: 0-7; FP: 0-5; Misc: 0-1 |
| 统一扁平化 | 0-15 |
在此示例中,备用 FP 寄存器文件中的寄存器 %f1 可以通过相对扁平化索引 4 以及相对未扁平化索引 1、统一未扁平化索引 9 或统一扁平化索引 12 引用。请注意,相对索引和统一索引之间的差异始终为 8(无论是否扁平化),未扁平化和扁平化索引之间的差异为 3(无论相对还是统一状态)。 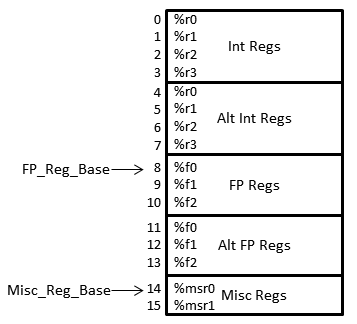
注意事项
- 尽管 gem5 代码对于特定函数期望哪种类型的寄存器索引并不总是清楚,但名称包含寄存器类的函数(例如,readIntReg())期望相对寄存器索引,而期望扁平化索引的函数通常在函数名称中有 “flat”。
- 虽然一般情况很复杂,但常见情况可能看似简单。例如,由于整数寄存器从统一寄存器空间的开头开始,因此相对和统一寄存器索引对于整数寄存器是相同的。此外,在没有(或很少使用)备用整数寄存器的架构中,未扁平化和扁平化索引(几乎总是)也是相同的,这意味着在这种情况下所有四种类型的寄存器索引都是可互换的。虽然这种情况似乎是一种简化,但它也往往掩盖了使用错误寄存器索引类型的错误。
- 上面的描述旨在说明这些索引类型的典型用法。可能有不完全遵循此描述的例外情况,但我厌倦了在每句话中写“通常”。
- 术语“相对”和“统一”是为本文档的使用而发明的,因此在代码开始赶上此页面之前,您不太可能在代码中看到它们。
- 此讨论仅涉及架构寄存器。诸如 O3 之类的乱序 CPU 模型通过将这些架构寄存器(使用扁平化寄存器索引)重命名为底层物理寄存器文件,增加了一层复杂性。
ISA 和 CPU 独立性
gem5 试图保持 CPU 模型 ISA 独立,以便更轻松地将任何 ISA 与不同的 CPU 模型一起使用。gem5 依靠两个通用接口来实现这种独立性:静态指令和执行上下文(上面都讨论过)。 静态指令允许 CPU 管理指令,执行上下文允许 ISA 或指令与 CPU 交互。下图提供了 gem5 中哪些组件是 ISA 依赖或独立的高级概述:

上图来源: Modular ISA-Independent Full-System Simulation (Ch 5 of Processor and System-on-Chip Simulation), G. Black, N. Binkert, and S. Reinhardt, A. Saidi. 链接。