last edited: 2026-01-30 06:21:33 +0000
gem5 内存系统
本文档描述了 gem5 中的内存子系统,重点关注 CPU 简单内存事务(读取或写入)期间的程序流程。
模型层次结构
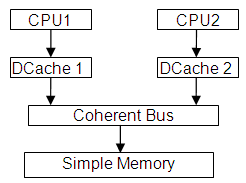
本文档中使用的模型由两个乱序 (O3) ARM v7 CPU 以及相应的 L1 数据缓存和简单内存组成。它是通过使用以下参数运行 gem5 创建的:
configs/example/fs.py –-caches –-cpu-type=arm_detailed –-num-cpus=2
Gem5 使用 Simulation Objects 派生对象作为构建内存系统的基本块。它们通过已建立主/从层次结构的端口连接。数据流在主端口上启动,而响应消息和 snoop 查询出现在从端口上。
CPU
Data Cache 对象实现了标准缓存结构:
详细描述 O3 CPU 模型不在本文档的范围内,因此这里仅提供有关该模型的几条相关说明:
读取访问 通过向 DCache 对象发送消息来启动。如果 DCache 拒绝该消息(因为被阻塞或忙碌),CPU 将刷新流水线,稍后将重新尝试访问。访问在收到来自 DCache 的回复消息 (ReadRep) 时完成。
写入访问 通过将请求存储到存储缓冲区来启动,该缓冲区的上下文在每个 tick 被清空并发送到 DCache。DCache 也可能拒绝该请求。当收到来自 DCache 的写入回复 (WriteRep) 消息时,写入访问完成。
加载和存储缓冲区(用于读取和写入访问)不对活动内存访问的数量施加任何限制。因此,未完成的 CPU 内存访问请求的最大数量不受 CPU 模拟对象的限制,而是受底层内存系统模型的限制。
拆分内存访问 已实现。
CPU 发送的消息包含访问区域的内存类型(Normal, Device, Strongly Ordered 和 cachebility)。但是,采用更简化的内存类型方法的模型的其余部分并未使用此信息。
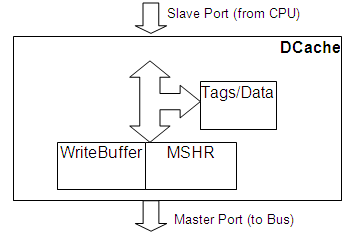
数据缓存对象
Data Cache 对象实现了标准缓存结构:
与特定缓存标记匹配(设置了 Valid 和 Read 标志)的 缓存内存读取 将在可配置的时间后完成(通过向 CPU 发送 ReadResp)。否则,请求将转发到 Miss Status and Handling Register (MSHR) 块。
与特定缓存标记匹配(设置了 Valid、Read 和 Write 标志)的 缓存内存写入 将在相同的可配置时间后完成(通过向 CPU 发送 WriteResp)。否则,请求将转发到 Miss Status and Handling Register (MSHR) 块。
未缓存的内存读取 转发到 MSHR 块。
未缓存的内存写入 转发到 WriteBuffer 块。
被驱逐的(和脏的)缓存行 转发到 WriteBuffer 块。
如果以下任何一项为真,则 CPU 对 Data Cache 的访问将被阻止:
- MSHR 块已满。 (MSHR 缓冲区的大小是可配置的。)
- Writeback 块已满。(该块的缓冲区大小是可配置的。)
- 针对同一内存缓存行的未完成内存访问次数已达到可配置的阈值——有关详细信息,请参阅 MSHR 和 Write Buffer。
处于阻塞状态的 Data Cache 将拒绝来自从端口(来自 CPU)的任何请求,无论它会导致缓存命中还是未命中。请注意,主端口上的传入消息(响应消息和 snoop 请求)永远不会被拒绝。
未缓存内存区域上的 Cache 命中(根据 ARM ARM 是不可预测的行为)将使缓存行无效并从内存中获取数据。
标记和数据块
Cache 行(在源代码中称为块)被组织成具有可配置关联性和大小的集合。它们具有以下状态标志:
- Valid。它保存数据。地址标记有效
- Read。如果没有设置此标志,将不接受任何读取请求。例如,当缓存行等待写标志完成写访问时,它是有效且不可读的。
- Write。它可以接受写入。带有 Write 标志的缓存行标识 Unique 状态——没有其他缓存内存持有副本。
- Dirty。被驱逐时需要 Writeback。
如果地址标记匹配并且设置了 Valid 和 Read 标志,则读取访问将命中缓存行。如果地址标记匹配并且设置了 Valid、Read 和 Write 标志,则写入访问将命中缓存行。
MSHR 和写缓冲区队列
Miss Status and Handling Register (MSHR) 队列保存 CPU 的未完成内存请求列表,这些请求需要对较低内存级别进行读取访问。它们是:
- 缓存读取未命中。
- 缓存写入未命中。
- 未缓存读取。
WriteBuffer 队列保存以下内存请求:
- 未缓存写入。
- 来自被驱逐(和脏)缓存行的 Writeback。
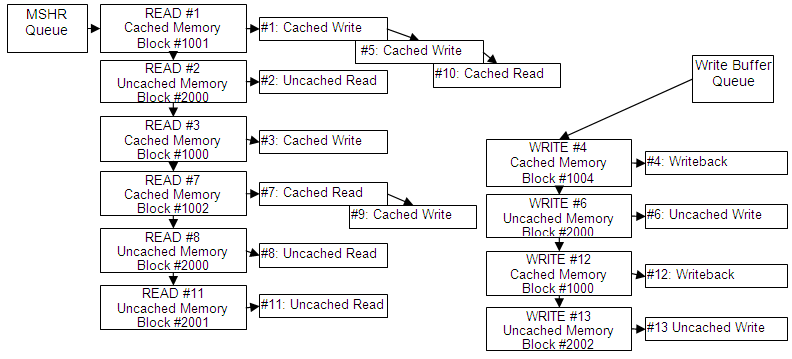
每个内存请求都被分配给相应的 MSHR 对象(上图中的 READ 或 WRITE),该对象代表必须读取或写入以完成命令的特定内存块(缓存行)。如上图所示,针对同一缓存行的缓存读/写共享一个公共 MSHR 对象,并将通过单个内存访问完成。
块的大小(以及对较低内存的读/写访问的大小)是:
- 对于缓存访问和写回,为缓存行的大小;
- 对于未缓存访问,为 CPU 指令中指定的大小。
通常,Data Cache 模型仅区分两种内存类型:
- 正常的 Cached 内存。它总是被视为写回、读分配和写分配。
- 正常的未缓存、设备和强有序类型被同等对待(作为未缓存内存)
内存访问排序
每个 CPU 读/写请求(当它们出现在从端口时)都被分配一个唯一的序列号。MSHR 对象的序列号是从第一个分配的读/写复制的。
来自这两个队列中每一个的内存读/写都是按顺序执行的(根据分配的序列号)。当两个队列都不为空时,模型将执行来自 MSHR 块的内存读取,除非 WriteBuffer 已满。但是,它将始终保留同一(或重叠)内存缓存行(块)上的读/写顺序。
总之:
- 对缓存内存的访问顺序不被保留,除非它们针对同一个缓存行。例如,访问 #1、#5 和 #10 将在同一个 tick 中同时完成(仍按顺序)。访问 #5 将在 #3 之前完成。
- 保留所有未缓存内存写入的顺序。Write#6 总是先于 Write#13 完成。
- 保留所有未缓存内存读取的顺序。Read#2 总是先于 Read#8 完成。
- 未缓存读写的顺序不一定保留,除非它们的访问区域重叠。因此,Write#6 总是先于 Read#8 完成(它们针对同一个内存块)。但是,Write#13 可能先于 Read#8 完成。
一致性总线对象

Coherent Bus 对象为 snoop 协议提供基本支持:
从端口上的所有请求都转发到相应的主端口。 对缓存内存区域的请求也转发到其他从端口(作为 snoop 请求)。
主端口回复转发到相应的从端口。
主端口 snoop 请求转发到所有从端口。
从端口 snoop 回复转发到作为请求源的端口。(请注意,snoop 请求的源可以是主端口或从端口。)
在发生以下任何事件后,总线会在可配置的时间段内声明自己处于阻塞状态:
- 数据包被发送(或未能发送)到从端口。
- 回复消息被发送到主端口。
- snoop 响应从一个从端口发送到另一个从端口。
处于阻塞状态的总线拒绝以下传入消息:
- 从端口请求。
- 主端口回复。
- 主端口 snoop 请求。
简单内存对象
它从不阻止从端口上的访问。
内存读/写立即生效。(收到请求时执行读取或写入)。
回复消息在可配置的时间段后发送。
消息流
内存访问排序
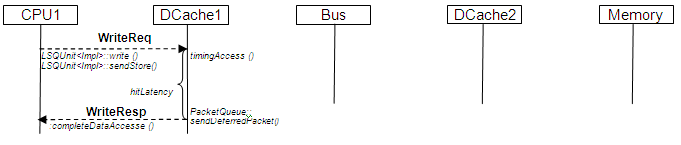
下图显示了命中具有 Valid 和 Read 标志的 Data Cache 行的读取访问:

缓存未命中读取访问将生成以下消息序列:
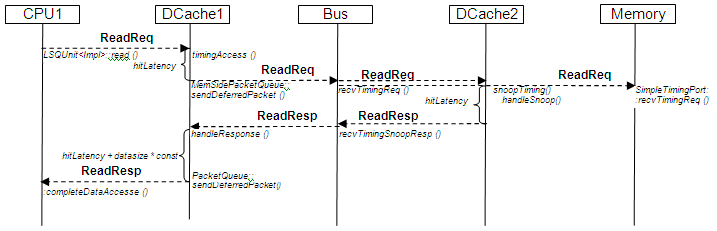
请注意,总线对象永远不会从 DCache2 和 Memory 对象都获得响应。它将完全相同的 ReadReq 包(消息)对象发送到内存和数据缓存。当 Data Cache 想要回复 snoop 请求时,它会用 MEM_INHIBIT 标志标记消息,该标志告诉 Memory 对象不要处理该消息。
内存访问排序
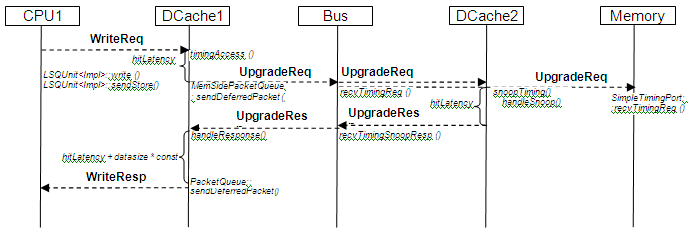
下图显示了命中具有 Valid 和 Write 标志的 DCache1 缓存行的写入访问:
下图显示了命中具有 Valid 但没有 Write 标志的 DCache1 缓存行的写入访问——这符合写入未命中的条件。DCache1 发出 UpgradeReq 以获得写入权限。DCache2::snoopTiming 将使被命中的缓存行无效。请注意,UpgradeResp 消息不携带数据。
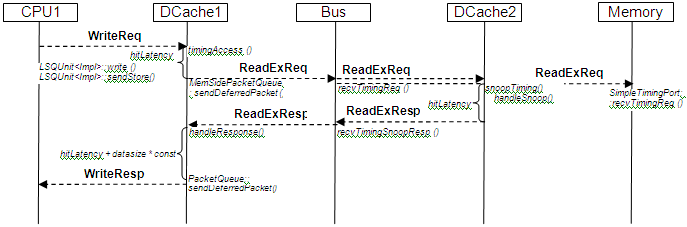
下图显示了 DCache 中的写入未命中。ReadExReq 使 DCache2 中的缓存行无效。ReadExResp 携带内存缓存行的内容。