
last edited: 2026-01-30 06:21:33 +0000
CHI
CHI ruby 协议提供了一个单一的缓存控制器,可以在缓存层次结构的多个级别重用,并配置为模拟 MESI 和 MOESI 缓存一致性协议的多个实例。此实现基于 Arm 的 AMBA 5 CHI 规范,并为大型 SoC 设计的设计空间探索提供了可扩展的框架。
CHI 概述和术语
CHI (Coherent Hub Interface) 提供了一种组件架构和事务级规范,用于对 MESI 和 MOESI 缓存一致性进行建模。CHI 定义了三个主要组件,如下图所示:
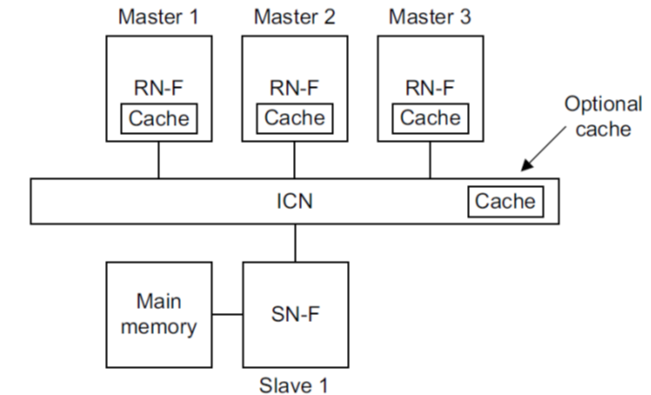
- 请求节点 (request node) 启动事务并向内存发送请求。请求节点可以是 完全一致的请求节点 (RNF),这意味着请求节点在本地缓存数据并应响应监听请求。
- 互连 (ICN),它是请求节点的响应者。在协议级别,互连是封装系统的 完全一致的主节点 (HNF) 的组件。
- 从节点 (SNF),它们与内存控制器接口。
HNF 是特定地址范围的一致性点 (PoC) 和序列化点 (PoS)。HNF 负责向 RNF 发出任何所需的监听请求或向 SNF 发出内存访问请求以完成事务。HNF 还可以封装共享的最后一级缓存并包含用于定向监听的目录。
CHI 规范 还为非一致性请求者 (RNI) 和非一致性地址范围 (HNI 和 SNI) 定义了特定类型的节点,例如属于 IO 组件的内存范围。在 Ruby 中,IO 访问不通过缓存一致性协议,因此仅实现了 CHI 的完全一致性节点类型。在本文档中,我们交替使用术语 RN / RNF,HN / HNF 和 SN / SNF。我们还使用术语 upstream (上游) 和 downstream (下游) 分别指代内存层次结构中上一级(即朝向 CPU)和下一级(即朝向内存)的组件。
协议概述
CHI 协议实现主要由两个控制器组成:
Memory_Controller(src/mem/ruby/protocol/chi/CHI-mem.sm) 实现 CHI 从节点。它接收来自主节点的内存读取或写入请求,并与 gem5 的经典内存控制器接口。Cache_Controller(src/mem/ruby/protocol/chi/CHI-cache.sm) 通用缓存控制器状态机。
为了允许完全灵活的缓存层次结构,Cache_Controller 可以配置为模拟请求节点和主节点内的任何缓存级别(例如 L1D、私有 L2、共享 L3)。此外,它还支持其他 Ruby 协议中不可用的多种功能:
- 为每种请求类型配置缓存块分配和释放策略。
- 统一或分离的传入和传出请求事务缓冲区。
- MESI 或 MOESI 操作。
- 目录和缓存标记及数据数组停顿。
- 用于在请求处理流程的多个步骤中注入延迟的参数。这使我们能够更紧密地校准性能。
该实现定义了以下缓存状态:
I: 行无效SC: 行是共享且干净的 (Shared Clean)UC: 行是独占/唯一且干净的 (Unique Clean)SD: 行是共享且脏的 (Shared Dirty)UD: 行是独占/唯一且脏的 (Unique Dirty)UD_T: 带超时的UD。当存储条件失败并导致行从 I 转换为 UD 时,如果失败次数超过某个阈值(配置定义),我们会转换为UD_T。在UD_T中,该行在给定的周期数(也是配置定义的)内不能从请求者驱逐;之后行变为 UD。这是为了避免某些情况下的活锁所必需的。
下图概述了控制器配置为 L1 缓存时的状态转换:

转换标有来自 cpu 的传入请求(或内部生成的,例如 Replacements)和向下游发送的结果传出请求。为了简单起见,该图省略了不改变状态的请求(例如,缓存命中)和无效监听(最终状态始终为 I)。为了简单起见,它也只显示了 MOESI 协议中的典型状态转换。在 CHI 中,最终状态最终将由响应者返回的数据类型决定(例如,请求者可能会收到 UD 或 UC 数据作为对 ReadShared 的响应)。
下图显示了 中间级 缓存控制器(例如,私有 L2,共享 L3,HNF 等)的转换:


与前一种情况一样,为了简单起见省略了缓存命中。除了缓存状态外,还定义了以下目录状态以跟踪上游缓存中存在的行:
RU: 上游请求者拥有行且处于 UC 或 UDRSC: 一个或多个上游请求者拥有行且处于 SCRSD: 一个上游请求者拥有行且处于 SD;其他人可能拥有 SCRUSC:RSC+ 当前域仍具有独占访问权限RUSD:RSD+ 当前域仍具有独占访问权限
当该行同时存在于本地缓存和上游缓存中时,可能有以下组合状态:
UD_RSC,SD_RSC,UC_RSC,SC_RSCUD_RU,UC_RUUD_RSD,SD_RSD
RUSC 和 RUSD 状态(上图中省略)用于跟踪控制器仍具有独占访问权限但不在其本地缓存中的行。这在非包含 (non-inclusive) 缓存中是可能的,其中本地块可以被释放而无需反向无效上游副本。
当缓存控制器是 HNF(主节点)时,状态事务与中间级缓存基本相同,除了以下差异:
- 发送
ReadNoSnp以从下游获取数据,因为唯一的下游组件是 SN(从节点)。 - 在缓存和目录未命中时,如果启用了 DMT(直接内存传输),则使用它。
- 在缓存未命中和目录命中时,如果启用了 DCT(直接缓存传输),则使用它。
有关 DCT 和 DMT 事务的更多信息,请参见 CHI 规范 中的第 1.7 节和第 2.3.1 节。DMT 和 DCT 是 CHI 功能,允许请求的数据源直接将数据发送给原始请求者。在 DMT 请求中,SN 直接将数据发送给 RN(而不是先发送给 HN,然后再转发给 RN),而在 DCT 中,HN 请求被监听的 RN(监听对象)直接将行的副本发送给原始请求者。启用 DCT 后,HN 还可以请求监听对象将数据发送给 HN 和原始请求者,以便 HN 也可以缓存数据。这取决于配置参数定义的分配策略。请注意,分配策略也会改变缓存状态转换。为了简单起见,上图说明了一个包含式缓存。
以下是影响协议行为的缓存控制器的主要配置参数列表(有关详细信息和完整参数列表,请参阅协议 SLICC 规范)
downstream_destinations: 定义发送到下游的请求的目的地,用于构建缓存层次结构。有关如何为每个核心设置具有私有 L1I、L1D 和 L2 缓存的系统的示例,请参阅configs/ruby/CHI.py中的create_system函数。is_HN: 当控制器用作主节点和地址范围的一致性点时设置。对于其他每个缓存级别必须为 false。enable_DMT和enable_DCT: 当控制器是主节点时,这将启用传入读取请求的直接内存传输和直接缓存传输。allow_SD: 允许共享脏状态。这在 MOESI 和 MESI 操作之间切换。alloc_on_readshared,alloc_on_readunique, 和alloc_on_readonce: 是否分配缓存块以存储用于响应相应读取请求的数据。alloc_on_writeback: 是否分配缓存块以存储从写回请求接收的数据。dealloc_on_unique和dealloc_on_shared: 如果行在上游缓存中变为唯一或共享,则释放本地缓存块。dealloc_backinv_unique和dealloc_backinv_shared: 如果本地缓存块因替换而被释放,还会使上游缓存中的行的任何唯一或共享副本无效。number_of_TBEs,number_of_snoop_TBEs, 和number_of_repl_TBEs: TBE 表中用于传入请求、传入监听和替换的条目数。unify_repl_TBEs: 替换使用与触发它的请求相同的 TBE 插槽。在这种情况下,忽略number_of_repl_TBEs。
这些参数影响缓存控制器性能:
read_hit_latency和read_miss_latency: 本地缓存命中或未命中的读取请求的流水线延迟。snoop_latency: 传入监听的流水线延迟。write_fe_latency和write_be_latency: 处理写入请求的前端和后端流水线延迟。前端延迟应用于发送确认响应和采取下一个行动之间。后端应用于接收确认和发送写入数据的请求者之间。allocation_latency: TBE 分配和事务初始化之间的延迟。cache: 附加到此控制器的CacheMemory包括大小、关联性、标记和数据延迟以及 bank 数量等参数。
第 协议实现 节概述了协议实现,而第 支持的 CHI 事务 节描述了实现的 AMBA 5 CHI 规范子集。接下来的部分参考协议源代码中的特定文件,并包括协议的 SLICC 片段。与实际的 SLICC 规范相比,一些片段略有简化。
协议实现
下图概述了缓存控制器实现。

在 Ruby 中,通过使用 SLICC 语言定义状态机来实现缓存控制器。状态机中的转换由到达输入队列的消息触发。在我们的特定实现中,为每个 CHI 通道定义了单独的传入和传出消息队列。传入的请求和监听消息,如果是开始新事务的消息,则通过相同的 请求分配 (Request allocation) 过程,在此过程中我们分配一个事务缓冲区条目 (TBE) 并将请求或监听移动到准备好启动的事务的内部队列。如果事务缓冲区已满,则拒绝请求并发送重试消息。
从 input / rdy 队列中出队的消息要执行的操作取决于目标缓存行的状态。如果行在本地缓存,则行的数据状态存储在缓存中,如果行存在于任何上游缓存中,则目录状态存储在目录条目中。对于具有未完成请求的行,瞬态存储在 TBE 中,并在事务完成时复制回缓存和/或目录。下图描述了事务生命周期的各个阶段以及缓存控制器中主要组件(输入/输出端口、TBETable、Cache、Directory 和 SLICC 状态机)之间的交互。后续部分将更详细地描述这些阶段。
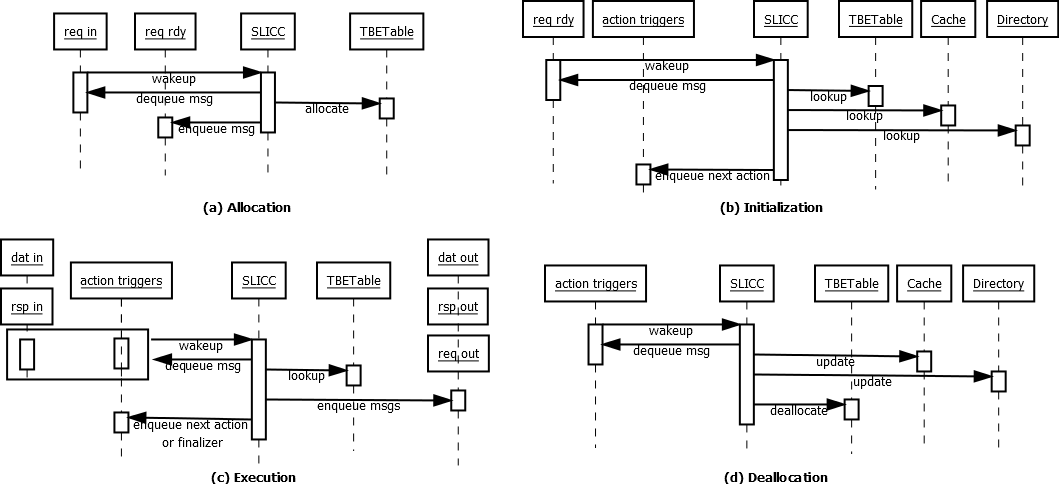
事务分配
下面的代码片段显示了如何处理 reqIn 端口中的传入请求。reqIn 端口从 CHI 的请求通道接收传入消息:
in_port(reqInPort, CHIRequestMsg, reqIn) {
if (reqInPort.isReady(clockEdge())) {
peek(reqInPort, CHIRequestMsg) {
if (in_msg.allowRetry) {
trigger(Event:AllocRequest, in_msg.addr,
getCacheEntry(in_msg.addr), getCurrentActiveTBE(in_msg.addr));
} else {
trigger(Event:AllocRequestWithCredit, in_msg.addr,
getCacheEntry(in_msg.addr), getCurrentActiveTBE(in_msg.addr));
}
}
}
}
allowRetry 字段指示可以重试的消息。无法重试的请求仅由先前收到信用的请求者发送(请参阅 CHI 规范中的 RetryAck 和 PCrdGrant)。由 Event:AllocRequest 或 Event:AllocRequestWithCredit 触发的转换执行单个操作,该操作要么在 TBE 表中为请求保留空间并将其移动到 reqRdy 队列,要么发送 RetryAck 消息:
action(AllocateTBE_Request) {
if (storTBEs.areNSlotsAvailable(1)) {
// 为此请求保留一个插槽
storTBEs.incrementReserved();
// 将请求移动到 rdy 队列
peek(reqInPort, CHIRequestMsg) {
enqueue(reqRdyOutPort, CHIRequestMsg, allocation_latency) {
out_msg := in_msg;
}
}
} else {
// 我们没有资源来跟踪此请求;排队重试
peek(reqInPort, CHIRequestMsg) {
enqueue(retryTriggerOutPort, RetryTriggerMsg, 0) {
out_msg.addr := in_msg.addr;
out_msg.event := Event:SendRetryAck;
out_msg.retryDest := in_msg.requestor;
retryQueue.emplace(in_msg.addr,in_msg.requestor);
}
}
}
reqInPort.dequeue(clockEdge());
}
注意我们不直接从此操作创建和发送 RetryAck 消息。相反,我们在内部 retryTrigger 队列中创建一个单独的触发事件。这是为了防止资源停顿停止此操作。下面的 性能建模 部分更详细地解释了资源停顿。
来自 Sequencer 对象(当控制器用作 L1 缓存时通常连接到 CPU)的传入请求和通过 seqIn 和 snpIn 端口到达的监听请求的处理方式类似,除了:
- 它们不支持重试。如果没有可用的 TBE,则会生成资源停顿,我们在下一个周期重试。
- 监听从单独的 TBETable 分配 TBE 以避免死锁。
事务初始化
一旦请求被分配了 TBE 并移动到 reqRdy 队列,就会触发一个事件来启动事务。我们为每种不同的请求类型触发不同的事件:
in_port(reqRdyPort, CHIRequestMsg, reqRdy) {
if (reqRdyPort.isReady(clockEdge())) {
peek(reqRdyPort, CHIRequestMsg) {
CacheEntry cache_entry := getCacheEntry(in_msg.addr);
TBE tbe := getCurrentActiveTBE(in_msg.addr);
trigger(reqToEvent(in_msg.type), in_msg.addr, cache_entry, tbe);
}
}
}
根据行的初始状态,每个请求都需要不同的初始化操作。为了说明此过程,让我们以处于 SC_RSC 状态(本地缓存中的共享干净和上游缓存中的共享干净)的行的 ReadShared 请求为例:
transition(SC_RSC, ReadShared, BUSY_BLKD) {
Initiate_Request;
Initiate_ReadShared_Hit;
Profile_Hit;
Pop_ReqRdyQueue;
ProcessNextState;
}
Initiate_Request初始化分配的 TBE。此操作将分配在本地缓存和目录中的任何状态和数据复制到 TBE。Initiate_ReadShared_Hit设置为完成此特定请求所需执行的操作集(见下文)。Profile_Hit更新缓存统计信息。Pop_ReqRdyQueue从reqRdy队列中删除请求消息。ProcessNextState执行Initiate_ReadShared_Hit定义的下一个操作。
Initiate_ReadShared_Hit 定义如下:
action(Initiate_ReadShared_Hit) {
tbe.actions.push(Event:TagArrayRead);
tbe.actions.push(Event:ReadHitPipe);
tbe.actions.push(Event:DataArrayRead);
tbe.actions.push(Event:SendCompData);
tbe.actions.push(Event:WaitCompAck);
tbe.actions.pushNB(Event:TagArrayWrite);
}
tbe.actions 存储完成操作所需触发的事件列表。在这种特定情况下,TagArrayRead、ReadHitPipe 和 DataArrayRead 引入延迟来模拟缓存控制器流水线延迟以及读取缓存/目录标记数组和缓存数据数组(参见 性能建模 部分)。SendCompData 设置并发送 ReadShared 请求的数据响应,WaitCompAck 设置 TBE 以等待来自请求者的完成确认。最后,TagArrayWrite 引入更新目录状态以跟踪新共享者的延迟。
事务执行
初始化后,该行将转换到 BUSY_BLKD 状态,如 transition(SC_RSC, ReadShared, BUSY_BLKD) 所示。BUSY_BLKD 是一个瞬态,表示该行现在有一个未完成的事务。在此状态下,事务由 rspIn 和 datIn 端口中的传入响应消息或 tbe.actions 中定义的触发事件驱动。
ProcessNextState 操作负责检查 tbe.actions 并将触发事件消息入队到 actionTriggers,在所有转换到 BUSY_BLKD 状态结束时执行。ProcessNextState 首先检查挂起的响应消息。如果没有挂起的消息,它将消息入队到 actionTriggers 以触发 tbe.actions 头部的事件。如果有挂起的响应,则 ProcessNextState 不做任何事情,因为事务将在收到所有预期响应后继续进行。
挂起的响应由 TBE 中的 expected_req_resp 和 expected_snp_resp 字段跟踪。例如,由 WaitCompAck 触发的转换执行的 ExpectCompAck 操作定义如下:
action(ExpectCompAck) {
tbe.expected_req_resp.addExpectedRespType(CHIResponseType:CompAck);
tbe.expected_req_resp.addExpectedCount(1);
}
这会导致事务等待直到收到 CompAck 响应。
允许在事务有挂起响应时执行某些操作。这些操作使用 tbe.actions.pushNB(即推送/非阻塞)入队。在上面的示例中,tbe.actions.pushNB(Event:TagArrayWrite) 模拟了在事务等待 CompAck 响应时执行的标记写入。
事务完成
当事务没有更多挂起响应且 tbe.actions 为空时,事务结束。ProcessNextState 检查此条件并将“终结器”触发消息入队到 actionTriggers。在处理此事件时,当前的缓存行状态和共享/所有权信息决定了该行的最终稳定状态。如有必要,将在缓存和目录中更新数据和状态信息,并释放 TBE。
冒险处理
每个控制器只允许每行缓存一个活动事务。如果新请求或监听在缓存行处于瞬态时到达,这会产生 CHI 标准中定义的冒险。我们按如下方式处理冒险:
请求冒险: 如前所述分配 TBE,但新事务的初始化被延迟,直到当前事务完成且该行回到稳定状态。这是通过将请求消息从 reqRdy 移动到单独的 stall buffer 来完成的。当当前事务完成时,所有停顿的消息都会添加回 reqRdy,并按原始到达顺序进行处理。
监听冒险: CHI 规范不允许现有请求停顿监听。如果事务正在等待发送到下游的请求的响应(例如,我们发送了 ReadShared 并且正在等待数据响应),我们必须接受并处理监听。只有当请求已被响应者接受并且保证完成(例如,具有挂起数据但也收到 RespSepData 响应的 ReadShared)时,监听才可以停顿。为了区分这些情况,我们使用 BUSY_INTR 瞬态。
BUSY_INTR 表示事务可以被监听中断。当针对处于此状态的行到达监听时,如前所述分配监听 TBE,并根据当前活动的 TBE 初始化其状态。然后监听 TBE 成为当前活动的 TBE。在释放监听之前,监听引起的任何缓存状态和共享/所有权更改都将复制回原始 TBE。当针对处于 BUSY_BLKD 状态的行到达监听时,我们将监听停顿,直到当前事务完成或转换为 BUSY_INTR。
性能建模
如前所述,当事务初始化时,缓存行状态立即可知,并且可以无延迟地读取和写入缓存行。这使得实现协议的功能方面变得更加容易。为了模拟时序,我们使用显式操作向事务引入延迟。例如,在 ReadShared 代码片段中:
action(Initiate_ReadShared_Hit) {
tbe.actions.push(Event:TagArrayRead);
tbe.actions.push(Event:ReadHitPipe);
tbe.actions.push(Event:DataArrayRead);
tbe.actions.push(Event:SendCompData);
tbe.actions.push(Event:WaitCompAck);
tbe.actions.pushNB(Event:TagArrayWrite);
}
TagArrayRead、ReadHitPipe、DataArrayRead 和 TagArrayWrite 没有任何功能意义。它们的存在是为了引入真实缓存控制器流水线中存在的延迟,在本例中为:标记读取延迟、命中流水线延迟、数据数组读取延迟和标记更新延迟。这些操作引入的延迟由配置参数定义。
除了显式添加的延迟外,SLICC 还有 资源停顿 (resource stalls) 的概念来模拟资源争用。给定转换期间执行的一组操作,SLICC 编译器自动生成检查这些操作所需的所有资源是否可用的代码。如果有任何资源不可用,则会生成资源停顿并且不执行转换。导致资源停顿的消息保留在输入队列中,协议尝试在下一个周期再次触发转换。
SLICC 编译器以不同方式检测资源:
- 隐式。这是输出端口的情况。如果操作将新消息入队,则会自动检查输出端口的可用性。
- 将
check_allocate语句添加到操作中。 - 使用资源类型注释转换。
我们使用 (2) 来检查 TBE 的可用性。参见下面的代码片段:
action(AllocateTBE_Snoop) {
// No retry for snoop requests; just create resource stall
check_allocate(storSnpTBEs);
...
}
这会向 SLICC 编译器发出信号,要求在执行任何包含 AllocateTBE_Snoop 操作的转换之前检查 storSnpTBEs 结构是否有可用的 TBE 插槽。
下面的代码片段举例说明了 (3):
transition({BUSY_INTR,BUSY_BLKD}, DataArrayWrite) {DataArrayWrite} {
...
}
DataArrayWrite 注释向 SLICC 编译器发出信号,要求检查 DataArrayWrite 资源类型的可用性。这些注释中使用的 资源请求类型 必须由协议显式定义,以及如何检查它们。在我们的协议中,我们定义了以下类型来检查缓存标记和数据数组中 bank 的可用性:
enumeration(RequestType) {
TagArrayRead;
TagArrayWrite;
DataArrayRead;
DataArrayWrite;
}
void recordRequestType(RequestType request_type, Addr addr) {
if (request_type == RequestType:DataArrayRead) {
cache.recordRequestType(CacheRequestType:DataArrayRead, addr);
}
...
}
bool checkResourceAvailable(RequestType request_type, Addr addr) {
if (request_type == RequestType:DataArrayRead) {
return cache.checkResourceAvailable(CacheResourceType:DataArray, addr);
}
...
}
当我们在事务上使用注释时,SLICC 编译器需要 checkResourceAvailable 和 recordRequestType 的实现。
缓存块分配和替换建模
考虑以下针对 ReadShared 未命中的事务初始化代码:
action(Initiate_ReadShared_Miss) {
tbe.actions.push(Event:ReadMissPipe);
tbe.actions.push(Event:TagArrayRead);
tbe.actions.push(Event:SendReadShared);
tbe.actions.push(Event:SendCompData);
tbe.actions.push(Event:WaitCompAck);
tbe.actions.push(Event:CheckCacheFill);
tbe.actions.push(Event:TagArrayWrite);
}
所有修改缓存行或作为监听或向下游发送请求的结果接收缓存行数据的事务都使用 CheckCacheFill 操作触发事件。此事件触发一个执行以下操作的转换:
- 检查我们是否需要将当前缓存行数据存储在本地缓存中。
- 检查我们是否已经为此行分配了缓存块。如果没有,尝试分配一个块。如果块不可用,则选择一个受害者块进行替换。
- 模拟缓存填充的延迟。
当执行替换时,会初始化一个新的事务来跟踪向下游发送的任何 WriteBack 或 Evict 请求和/或用于反向无效的监听(如果缓存控制器配置为强制包含)。根据配置参数,替换的 TBE 使用来自专用 TBETable 的资源或重用触发替换的 TBE 的相同资源。在这两种情况下,触发替换的事务都会在不等待替换过程的情况下完成。
注意 CheckCacheFill 实际上并不将数据写入缓存块。如果只需要确保分配缓存块,触发替换,并模拟缓存填充延迟。如前所述,如果需要,TBE 数据会在事务完成期间复制到缓存。
支持的 CHI 事务
所有事务均按照 AMBA5 CHI Issue D 规范 中的描述实施。下一节提供了对未由公开文档固定的特定于实现的选项的更详细说明。
支持的请求
支持以下传入请求:
ReadSharedReadNotSharedDirtyReadUniqueCleanUniqueReadOnceWriteUniquePtl和WriteUniqueFull
当接收到任何请求时,包含性配置参数会在事务初始化期间进行评估,并且在为请求分配的事务缓冲区条目中设置 doCacheFill 和 dataToBeInvalid 标志。doCacheFill 表示我们应该在本地缓存中保留该行的任何有效副本;dataToBeInvalid 表示我们在完成事务时必须使本地副本无效。
当接收到 ReadShared 或 ReadUnique 时,如果数据以所需状态存在于本地缓存中(例如 ReadUnique 为 UC 或 UD),则向请求者发送 CompData 响应。响应类型取决于 dataToBeInvalid 的值。
- 如果
dataToBeInvalid==true- 始终传播 unique 和/或 dirty 状态
- 对于
ReadNotSharedDirty,如果本地状态为SD并且使用WriteCleanFull写回该行,则始终发送CompData_SC
- 否则:
- 响应
ReadUnique:传播 dirty 状态,即CompData_UD或CompData_UC。 - 响应
ReadShared或ReadNotSharedDirty:发送CompData_SC。如果设置了fwd_unique_on_readshared配置参数,并且该行没有其他共享者,则ReadShared将作为ReadUnique处理。
- 响应
当接收到 ReadOnce 时,如果数据存在于本地缓存中,则始终发送 CompData_I。对于 WriteUniquePtl 处理,请参见下文。
如果发生缓存未命中,可能会执行多种操作,具体取决于 doCacheFill 和 dataToBeInvalid==false 是否成立;以及是否启用了 DCT 或 DMT:
ReadShared/ReadNotSharedDirty:- 如果目录状态是
RSD或RU:- 如果 DCT 禁用:向所有者发送
SnpShared;在本地缓存该行(如果doCacheFill)并向请求者发送响应。 - 如果 DCT 启用:向所有者发送
SnpSharedFwd;如果doCacheFill==true,则设置retToSrc字段以便可以在本地缓存该行。
- 如果 DCT 禁用:向所有者发送
- 如果目录状态是
RSC:- 如果 DCT 禁用:向其中一个共享者发送
SnpOnce;在本地缓存该行(如果doCacheFill)并向请求者发送响应。 - 如果 DCT 启用:向其中一个共享者发送
SnpSharedFwd;如果doCacheFill==true,则设置retToSrc字段以便可以在本地缓存该行。
- 如果 DCT 禁用:向其中一个共享者发送
- 否则:发出
ReadShared/ReadNotSharedDirty或ReadNoSnp(如果是 HNF)。在 HNF 配置中,如果启用了 DMT,则使用 DMT 发出ReadNoSnp。 - 对于
ReadNotSharedDirty,改为发送SnpNotSharedDirty和SnpNotSharedDirtyFwd。
- 如果目录状态是
ReadUnique:- 如果目录状态是
RU,RUSD,RUSC:- 如果 DCT 禁用或包含性为 inclusive:向所有者发送
SnpUnique;在本地缓存该行(如果doCacheFill)并向请求者发送响应。 - 如果 DCT 启用且包含性为 exclusive:向所有者发送
SnpUniqueFwd。
- 如果 DCT 禁用或包含性为 inclusive:向所有者发送
- 如果目录状态是
RSC/RSD:- 发送带有
retToSrc=true的SnpUnique以使共享者无效并获取脏行(在RSD情况下) - 如果不是 HNF:向下游发送
CleanUnique以获得唯一权限。
- 发送带有
- 否则:发出
ReadUnique或ReadNoSnp(如果是 HNF)。在 HNF 配置中,如果启用了 DMT,则使用 DMT 发出ReadNoSnp。 - 对于
RUSC和RSC,如果有多个共享者,则只选择一个共享者作为上述监听的目标。其他共享者使用带有retToSrc=false的SnpUnique无效。
- 如果目录状态是
ReadOnce:- 如果存在目录条目:
- 如果 DCT 禁用:向其中一个共享者发送
SnpOnce;将收到的数据响应发送给请求者。 - 如果 DCT 启用:向其中一个共享者发送
SnpOnceFwd。
- 如果 DCT 禁用:向其中一个共享者发送
- 否则:发出
ReadOnce或ReadNoSnp(如果是 HNF)。在 HNF 配置中,如果启用了 DMT,则使用 DMT 发出ReadNoSnp。
- 如果存在目录条目:
CleanUnique:- 向除原始请求者之外的所有共享者/所有者发送
SnpCleanInvalid。 - 如果不是 HNF:向下游发送
CleanUnique以获得唯一权限。 - 如果有脏行,请求者有干净行,并且
doCacheFill==false:使用WriteCleanFull写回该行。
- 向除原始请求者之外的所有共享者/所有者发送
WriteUniquePtl/WriteUniqueFull:- 如果数据以 UC 或 UD 状态存在于本地缓存中:
- 如果有任何共享者,则发出
SnpCleanInvalid。 - 在本地缓存中执行写入。
- 如果有任何共享者,则发出
- 如果本地没有 UC/UD 数据:
- 如果是 HNF:
- 如果有任何共享者,则发出
SnpCleanInvalid。 - 将任何收到的监听响应数据与 WriteUnique 数据合并。
- 如果有完整的行且设置了
doCacheFill,则在本地缓存该行,否则写回内存 (WriteNoSnp或WriteNoSnpPtl)。
- 如果有任何共享者,则发出
- 如果不是 HNF:
- 将
WriteUniquePtl和任何接收到的数据转发到下游缓存。 - 传入监听将导致任何本地缓存的数据在处理请求时变为无效。
- 将
- 如果是 HNF:
- 如果数据以 UC 或 UD 状态存在于本地缓存中:
支持的监听 (snoops)
缓存控制器发出并接受以下监听:
SnpShared和SnpSharedFwdSnpNotSharedDirty和SnpNotSharedDirtyFwdSnpUnique和SnpUniqueFwdSnpCleanInvalidSnpOnce和SnpOnceFwd
监听响应根据规范定义的行当前状态生成。根据数据状态和监听者设置的 retToSrc 的值返回数据。如果设置了 retToSrc,则监听响应始终包含数据。
SnpShared/SnpNotSharedDirty:- 如果行是脏的、唯一的或
retToSrc,监听对象总是返回数据。 - 如果监听者需要缓存该行,则设置
retToSrc。 - 最终监听对象状态始终为 shared clean。
- 如果行是脏的、唯一的或
SnpUnique:- 如果行是脏的、唯一的或
retToSrc,监听对象总是返回数据。 - 如果监听者需要缓存该行,则设置
retToSrc。 - 最终监听对象状态始终为 invalid。
- 如果行是脏的、唯一的或
SnpCleanInvalid:- 与 SnpUnique 相同,只是如果行是 unique 和 clean 的,则不返回数据。
SnpSharedFwd:- 如果监听者需要缓存该行,则设置
retToSrc。 - 如果脏,则行作为脏转发
- 最终监听对象状态始终为 shared clean
- 如果监听者需要缓存该行,则设置
SnpNotSharedDirtyFwd:- 如果监听者需要缓存该行,则设置
retToSrc。 - 如果行在监听对象处是脏的,则总是返回数据;行总是作为 clean 转发。
- 最终监听对象状态始终为 shared clean。
- 如果监听者需要缓存该行,则设置
SnpUniqueFwd:- 与 SnpUnique 相同,只是数据永远不会返回给监听者(如规范定义)
SnpOnce:- 总是以
retToSrc=true生成,并且监听对象总是返回数据。 - 在任何状态下都接受(除了 invalid)。最终监听对象状态不变。
- 总是以
SnpOnceFwd:- 与 SnpOnce 相同,只是数据永远不会返回给监听者。
如果监听对象在任何状态下都有共享者,则将相同的请求发送到上游的所有共享者。对于 SnpSharedFwd/SnpNotSharedDirtyFwd 和 SnpUniqueFwd,分别发送 SnpShared/SnpNotSharedFwd 或 SnpUnique。对于收到的 SnpOnce,仅当该行不在本地存在时才向上游发送 SnpOnce。在这个特定的实现中,总是有上游缓存拥有该行的目录条目。监听永远不会发送到没有该行的缓存。
写回和驱逐
当由于容量原因需要驱逐缓存行时(当前不支持缓存维护操作),控制器内部会触发写回。有关替换的更多信息,请参阅第 缓存块分配和替换建模 节。这些内部事件是根据控制器的配置参数生成的:
GlobalEviction: 从当前和所有上游缓存中驱逐一行。如果设置了dealloc_backinv_unique或dealloc_backinv_shared参数,则适用此操作。LocalEviction: 在不反向无效上游缓存的情况下驱逐一行。
首先我们释放本地缓存块(以便引起驱逐的请求可以分配新块并完成)。对于 GlobalEviction,向所有上游缓存发送 SnpCleanInvalid。一旦收到所有监听响应(可能有脏数据),就会执行 LocalEviction。LocalEviction 通过发出适当的请求来完成,如下所示:
WriteBackFull, 如果行是脏的WriteEvictFull, 如果行是唯一且干净的WriteCleanFull, 如果行是脏的,但有干净的共享者Evict, 如果行是共享且干净的
对于 HNF 配置,行为略有变化:使用向 SNF 的 WriteNoSnp 代替 WriteBackFull,如果行是干净的,则不发出请求。
WriteBack* 和 Evict 请求在下游缓存中处理如下:
WriteBackFull/WriteEvictFull/WriteCleanFull:- 如果
alloc_on_writeback,可能需要分配缓存块。如果没有空闲块,则会触发目标缓存组中缓存行的 LocalEviction。受害者行是根据cache参数指向的对象实现的替换策略选择的(可以单独配置)。 - 向请求者发送
CompDBIDResp。 - 收到数据后,更新本地缓存并从目录中删除请求者(如果
WriteBackFull/WriteEvictFull)。
- 如果
Evict:- 从目录中删除请求者并回复
Comp_I。
- 从目录中删除请求者并回复
冒险 (Hazards)
对当前有未完成事务的行的请求总是停顿,直到事务完成。在有未完成请求时收到的监听按照规范中的要求处理:
- 对于未完成的
CleanUnique:- 立即发送监听响应,并相应地更改当前行状态。
- 注意我们不模拟 CHI 规范中的 UCE 和 UDP 状态。如果行在请求者等待
CleanUnique响应时失效,它会立即跟进一个ReadUnique。
- 对于未完成的
WriteBackFull/WriteEvictFull/WriteCleanFull且尚未收到CompDBIDResp;或在收到Comp_I之前的 Evict:- 立即发送监听响应,并相应地更改当前行状态。
- 将被写回的行的状态将是监听之后的状态。
- 如果在当前事务等待来自上游缓存的监听响应时收到监听,则传入监听将停顿,直到收到所有来自上游的挂起响应并发送任何后续请求。这可能发生在以下情况:
- 在全局替换期间
- 接受的需要监听上游缓存的
ReadUnique
在有未完成事务时可能会收到多个监听。在这个特定的实现中,SnpShared 或 SnpSharedFwd 之后可能是 SnpUnique 或 SnpCleanInvalid。但是,不可能有来自下游缓存的并发监听。
传入请求和监听都需要分配 TBE。为了防止事务缓冲区满时出现死锁,使用单独的缓冲区来分配监听 TBE。监听不允许重试,因此如果监听 TBE 表已满,snpIn 端口中的消息将被停顿,可能会导致互连中监听通道的严重拥塞。
其他实现说明
- 如果 HNF 使用 DMT,如果设置了
enable_DMT_early_dealloc配置参数,它将发送ReadNoSnpSep而不是ReadNoSnp。这允许 HNF 更早地释放 TBE。 - 未实现 Order 位字段,因此除了
ReadNoSnpSep外,从不使用ReadReceipt响应。如果需要请求排序,则由 Ruby 通过在请求者处序列化请求来强制执行。在缓存控制器处,对同一行的请求按到达顺序处理。对不同行的请求可以按任何顺序处理,但是只要有可用资源,它们通常按到达顺序处理。 - 未实现独占访问和原子请求。Ruby 在定序器中有自己的全局监视器来管理独占加载和存储。原子操作也由 Ruby 处理,它们在协议级别只需要
ReadUnique。 - 规范中声明为可选时,总是发送
CompAck响应。请求者总是在完成事务和释放资源之前等待CompAck(如果需要或可选)。 - 仅对
WriteUnique请求使用单独的Comp和DBIDresp。在收到所有监听响应后发送DBIDresp;在DBIDresp之后发送Comp,并考虑前端写入延迟 (write_fe_latency)。 - 未实现内存属性字段。
- 未实现
DoNotGoToSD字段。 - 未实现
CBusy。 - 从不使用
WriteDataCancel响应。 - 未实现错误处理。
- 未实现缓存存储 (Cache stashing)。
- 未实现原子事务。
- 未实现 DMV 事务。
- 此实现不支持下面的协议表中未列出的任何请求。