
在 gem5 中建模核心
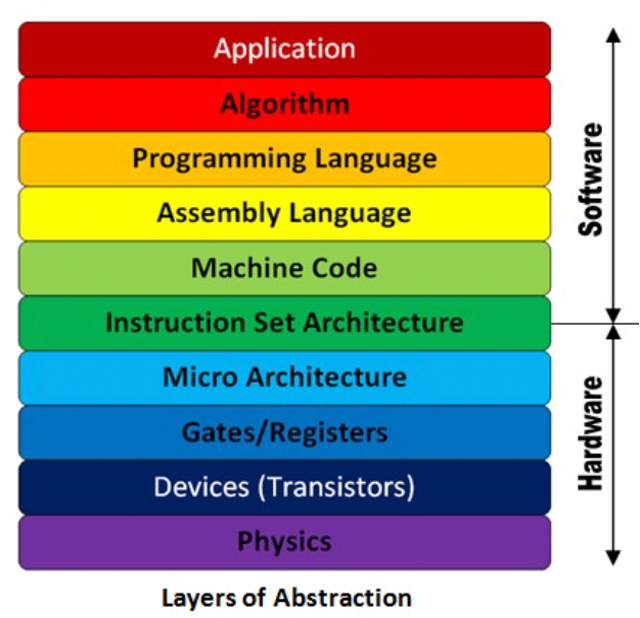
什么是 ISA?
指令集架构(ISA)是软件和硬件之间的接口。
ISA 定义了:
- 处理器可以执行的指令
- 可用的寄存器
- 内存模型
- 异常和中断处理
gem5 可以模拟的 ISA
- ARM
- RISC-V
- x86
- MIPS
- SPARC
实际上,你可能只会使用 ARM、RISC-V 和 x86。
其余的虽然可用,但测试或维护不够完善。
gem5 的 ISA-CPU 独立性
与真实硬件中 CPU 与其设计运行的 ISA 紧密耦合不同,gem5 通过解耦两者来简化问题。 这样做使得 gem5 的 CPU 模型变得与 ISA 无关(或者 ISA 变得与 CPU 模型无关)。
虽然这种独立性有限制,但目标是允许轻松添加和扩展新的 ISA 和 CPU 模型,而无需处理大量的代码更改和重写。 作为高级总结,这种独立性是通过为每个 ISA 设置一个独立的”解码器”来实现的,该解码器将指令转换为描述其行为的对象。
注意:我将在这里广泛使用”解码器”一词来描述解析指令的位和字节以确定其行为以及它应该如何与 CPU 模型交互的过程。在 gem5 中,这是 ISA 定义的一部分,用于”插入”到 CPU 模型中。
它的功能或职责与真实 CPU 中的解码器不同。
ISA-CPU 独立性示意图
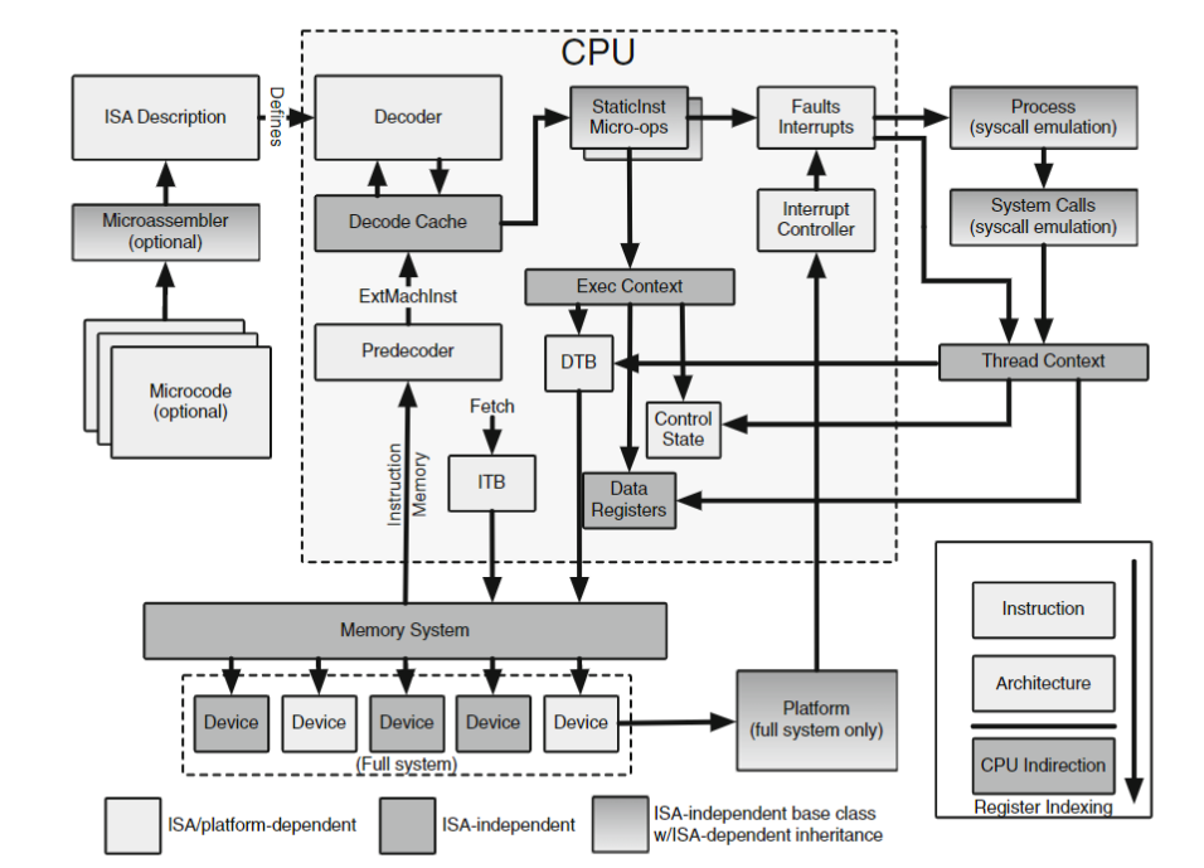
重要部分:StaticInst
这个复杂设计的重要要点是,无论解码器是为哪个 ISA 创建的,它都会将 CPU 接收到的指令解析为 StaticInst 对象。
StaticInst 是一个包含特定 ISA 指令的静态信息的对象,适用于该指令的所有实例。
它包含以下信息:
- 操作类
- 源寄存器和目标寄存器
- 标志,显示指令是否有微操作
- 定义指令行为的函数
execute()initiateAcc()completeAcc()disassemble()
DynamicInst
DynamicInst 对象包含特定指令实例的信息。
它是从 StaticInst 对象中的信息构造的。
它包含以下信息:
- PC 和预测的下一个 PC
- 指令结果
- 线程号
- CPU
- 重命名寄存器索引
- 提供
ExecContext接口
ExecContext
ExecContext 接口提供了指令以标准化方式与 CPU 模型交互的方法。
DynamicInst 对象实现了 ExecContext 接口。
gem5 中指令的执行过程
在这个例子中,我们将使用 GDB 来跟踪 gem5 中指令的执行。
首先,我们将通过 GDB 运行 materials/03-Developing-gem5-models/05-modeling-cores/01-inst-trace.py 中的脚本。
使用 GDB,我们将在 Add::Add 函数和 Add::execute 函数上添加断点。
首先,使用 gdb 运行 gem5:
gdb gem5
然后,在表示 Add 指令的 StaticInst 对象的函数上添加断点。
gem5 中指令的执行过程
在 Add::Add 函数上添加断点。
这只是 Add 类的构造函数。它创建表示 Add 指令的 StaticInst 对象。
(gdb) break Add::Add
然后在 Add::execute 函数上添加断点。
这是用于执行 Add 指令的函数。
(gdb) break Add::execute
开始执行 gem5:
(gdb) run 01-inst-trace.py
RISC-V Add::Add 回溯
你应该已经到达 Add::Add 函数中的第一个断点:
Breakpoint 1, 0x0000555555a3b1b0 in gem5::RiscvISAInst::Add::Add(unsigned int) ()
接下来我们将进行回溯。回溯显示到达当前函数所调用的函数。 让我们看看最后 10 个被调用的函数:
(gdb) bt 10
输出:
0 {PC} in gem5:: RiscvISAInst::Add: :Add(unsigned int) ()
1 {PC} in gem5:: RiscvISA:: Decoder: :decodeInst(unsigned long) ()
2 {PC} in gems:: RiscvISA: :Decoder: : decode(unsigned long, unsigned long)
3 {PC} in gem5:: RiscvISA: :Decoder:: decode (gem5:: PCStateBase&) ()
4 {PC} in gem5:: BaseSimpleCPU:: preExecute ()
5 {PC} in gem5:: TimingSimpleCPU:: IcachePort:: ITickEvent:: process () ()
6 {PC} in gem5:: EventQueue:: serviceone() ()
7 {PC] in gem5: :doSimLoop (gem5:: EventQueue*) ()
8 {PC} in gem5:: simulate(unsigned long) ()
9 {PC} in pybind11::pp_function:: initialize<gem5: :GlobalSimLoopExitEve ...
这里第 0 个函数调用是 Add::Add 函数。
每个后续索引是调用前一个函数的函数(即,第 1 个函数调用了第 0 个函数,第 2 个函数调用了第 1 个函数,等等)
第 5 个函数是 TimingSimpleCPU 模型的 process 函数,用于处理指令的函数。
索引 > 6 的函数是 gem5 的内部函数,在指令执行之前调用,我们在这里不需要关心。
4 {PC} in gem5:: BaseSimpleCPU:: preExecute ()
preExecute 是在 CPU 模型中执行指令之前调用的函数。它用于执行任何必要的设置。
你可以访问 gem5 仓库中的 “src/cpu/simple/base.cc” 来查看 BaseSimpleCPU 的 preExecute 函数。
回溯中的下一个函数是 RISC-V ISA 的解码器。
3 {PC} in gem5:: RiscvISA: :Decoder:: decode (gem5:: PCStateBase&) ()
这个函数是从 BaseSimpleCPU 的 preExecute 函数中的以下行调用的:
//Decode an instruction if one is ready. Otherwise, we'll have to
//fetch beyond the MachInst at the current pc.
instPtr = decoder->decode(pc_state);
你可以跟踪这个调用到 Decoder:: decode,它可以在 gem5 仓库的 src/arch/riscv/decoder.cc 中找到。
StaticInstPtr
Decoder::decode(PCStateBase &_next_pc)
{
if (!instDone)
return nullptr;
instDone = false;
auto &next_pc = _next_pc.as<PCState>();
if (compressed(emi)) {
next_pc.npc(next_pc.instAddr() + sizeof(machInst) / 2);
next_pc.compressed(true);
} else {
next_pc.npc(next_pc.instAddr() + sizeof(machInst));
next_pc.compressed(false);
}
emi.vl = next_pc.vl();
emi.vtype8 = next_pc.vtype() & 0xff;
emi.vill = next_pc.vtype().vill;
emi.rv_type = static_cast<int>(next_pc.rvType());
return decode(emi, next_pc.instAddr());
}
这个函数在调用 Decoder::decode(ExtMachInst mach_inst, Addr addr) 之前将下一条指令加载到解码器中。
StaticInstPtr
Decoder::decode(ExtMachInst mach_inst, Addr addr)
{
DPRINTF(Decode, "Decoding instruction 0x%08x at address %#x\n",
mach_inst.instBits, addr);
StaticInstPtr &si = instMap[mach_inst];
if (!si)
si = decodeInst(mach_inst);
si->size(compressed(mach_inst) ? 2 : 4);
DPRINTF(Decode, "Decode: Decoded %s instruction: %#x\n",
si->getName(), mach_inst);
return si;
}
解码函数
这个函数主要作为调用 Decoder::decodeInst 函数的简单包装器,加上设置大小和允许一些调试信息。
decodeInst 函数是回溯中的下一个函数,但它是_生成的_。
decideInst 函数是生成的代码,只有在你构建 gem5(scons build/ALL/gem5.opt -j$(nproc))时才会可用。
这些生成文件的副本已添加到 materials/03-Developing-gem5-models/05-modeling-cores/build-riscv-generated-files 供你参考。
这是 “decode-method.cc.inc” 的一个片段,移除了多余的行,以显示返回 Add 指令的语句路径:
// ...
case 0xc:
switch (FUNCT3) {
case 0x0:
switch (KFUNCT5) {
case 0x0:
switch (BS) {
case 0x0:
// ROp::add(['\n Rd = rvSext(Rs1_sd + Rs2_sd);\n '],{})
return new Add(machInst);
break;
这个解码函数接受机器指令并返回适当的 StaticInst 对象(Add(machInst))。
它只是一个巨大的映射表。
RISC-V Add::Execute 回溯
让我们在 GDB 中继续执行以到达下一个断点:
(gdb) c
如果成功,你应该看到以下输出:
Breakpoint 2, {PC} in gem5:: RiscvISAInst::Add::execute...
接下来,我们将进行回溯以查看到达当前函数所调用的函数:
(gdb) bt 5
如你所见,execute 函数是通过 TimingSimpleCPU 模型的 process 函数调用的。
以下代码可以在 “src/cpu/simple/timing.cc 中找到:
void
TimingSimpleCPU::IcachePort::ITickEvent::process()
{
cpu->completeIfetch(pkt);
}
然后继续到:
// non-memory instruction: execute completely now
Fault fault = curStaticInst->execute(&t_info, traceData);
这是调用 StaticInst 对象的 execute 函数的函数,它将执行指令的所有工作。
注意:这是因为 Add 是非内存指令。内存指令会立即执行。没有内存访问的指令被模拟为瞬时执行。
不同的内存访问和指令执行
StaticInst 对象有三个用于执行指令的函数:execute()、initiateAcc() 和 completeAcc()。
execute() 用于通过单个函数调用执行指令。
这在两种情况下使用:运行原子模式时和指令是非内存指令时。
initiateAcc() 用于通过内存系统启动内存访问。
它在请求内存系统执行访问之前,完成实际指令操作访问之前的所有工作。然后,内存系统最终会调用 completeAcc() 来完成访问并触发指令的执行。
后两个函数用于内存指令,例如定时内存访问模式以及当指令是内存指令时(即,指令从内存加载,因此需要时序信息)。
指令-CPU 控制流(SimpleCPU)

gem5 ISA 解析器
到目前为止,我们已经看到了指令如何在 gem5 中被解码然后执行。 然而,我们还没有看到这个解码过程是如何定义的,以及指令执行的行为是如何定义的。 这就是它变得复杂的地方…
ISA 规范和解析
“src/arch/*/isa” 目录包含 ISA 定义。 这是用我们称为 ISA 领域特定语言(ISA DSL)的专用语言编写的。
当构建 gem5 时,构建系统使用 src/arch/isa/isa_parser/isa_parser.py 脚本解析这些文件,该脚本生成必要的 CPP 代码。 这些生成的文件可以在 “build/ALL/arch/*/generated/” 中找到。 然后,gem5 构建系统将这些生成的文件编译到 gem5 二进制文件中。
重要的高级概念

ISA 定义的问题在于它非常间接,你可能会在试图理解 CPP 代码生成的小细节时迷失方向。
记住高级概念对于理解 ISA 是如何定义的以及指令是如何被解码和执行的更为重要。
痛苦的真相是,要扩展或添加到 ISA,大多数开发人员会使用 grep 查找类似的指令,并尝试理解涉及的模板,而不完全理解所有部分。
让我们尝试理解一条 RISC-V 指令
在下面,我们将查看 RISC-V 中的 LW 指令,以及它如何在 gem5 中被指定、解码和执行。
RISC-V 指令格式
要理解 RISC-V ISA 以及 gem5 RISC-V 解码器的工作原理,我们需要理解基本指令格式。 基本指令格式是 R、I、S、B、U 和 J 类型,它们使用以下格式:

- R 类型:用于寄存器-寄存器操作。
- I 类型:用于立即数和加载操作。
- S 类型:用于存储操作。
- B 类型:用于分支操作。
- U 类型:用于高位立即数操作。
- J 类型:用于跳转操作。
RISC-V 的”加载字”(LW)指令
加载字(指令:LW)是一条 I 类型指令,它将 32 位值从内存加载到寄存器中。
它由以下格式定义:
LW rd,offset(rs1) # rd = mem[rs1+imm]
lw是指令的助记符。rd是目标寄存器。imm立即数值:确定偏移量(可用于访问子字数据)。rs1是源寄存器。
它将源寄存器 rs1 的值加载到目标寄存器 rd + imm 中。如果 imm 为零,则 rs1 的完整字(32 位)被加载到 rd 中。这个 imm 值用于加载子字数据。但是,如果非零,imm 用于加载子字数据。imm 在加载到 rd 之前将 rs1 寄存器中的位进行移位。因此,如果 imm = 15,rs1 的值在加载到 rd 之前会移位 15 位。
RISC-V 的 LW 指令分解
考虑以下指令:
000000000000000000000000100100110001100011
这是一条 LW 指令,属于 I 类型指令。 因此,指令按如下方式分解:
| 31 -- 20 | 19 -- 15 | 14 -- 12 | 11 -- 7 | 6 -- 0 |
| 000000000001 | 00010 | 010 | 00011 | 000011 |
| imm | rs1 | func3 | rd | opcode |
在这个例子中,地址为 2 的寄存器(rs1,00010)被加载到地址为 3 的寄存器(rd,00011)中,偏移量为 1(imm)。funct3 是 LW 指令的功能代码(对于 LW 指令,这始终是 010),opcode 是 LW 指令的操作代码(也始终相同)。
注意:在 gem5 中,我们还提到 QUADRANT 或 QUAD,它是操作码的最后两位(在这种情况下是 11),以及 OPCODE5,它指的是 opcode 右移 2 位(基本上是没有 QUAD 的 opcode,在这种情况下是 0000)。
因此 opcode = (OPCODE5 « 2 )+ QUAD。
理解 LW 的解码
ISA 定义所做的是定义指令如何被分解,以及指令的”部分”(位域)如何用于解码指令。
转到 gem5 仓库中的 “src/arch/riscv/isa/bitfields.hsh” 目录。 下面是一个片段。
// Bitfield definitions.
//
def bitfield RVTYPE rv_type;
def bitfield QUADRANT <1:0>;
def bitfield OPCODE5 <6:2>;
这定义了位域,就像上一张幻灯片中描述的那样。 解码器使用这些位域来解码指令。
转到 “decoder.isa” 并搜索 lw 指令
以下显示了通过解析指令的 opcode 和 funct3 字段到达指令定义的路径:
# A reduced decoder.isa to focus just on the path to `lw`.
decode QUADRANT default Unknown::unknown() {
0x3: decode OPCODE5 { # if QUADRANT == 0x03; then decode OPCODE5
0x00: decode FUNCT3 { # if OPCODE5 == 0x00; then decode FUNCT3
format Load { # This tells use to use the `Load` format when decoding (more on this later)
0x2: lw({{ # if QU # if FUNCT3 == 0x02 then declare lw instruction
Rd_sd = Mem_sw;
}});
}
}
}
}
Rd_sd 是目标寄存器,Mem_sw 是要加载到目标寄存器中的内存地址。
从 LW ISA 定义生成代码
你可以并排比较 decoder.isa 和 decode-method.cc.inc,以查看 ISA 定义如何用于生成 CPP 解码器代码。
这是由 ISA 解析器脚本(isa_parser.py)完成的,gem5 构建系统使用它来生成 CPP 代码。
decode QUADRANT default Unknown::unknown() {
变成
using namespace gem5;
StaticInstPtr
RiscvISA::Decoder::decodeInst(RiscvISA::ExtMachInst machInst)
{
using namespace RiscvISAInst;
switch (QUADRANT) {
0x3: decode OPCODE5 {
变成
case 0x3:
switch (OPCODE5) {
0x00: decode FUNCT3 {
变成
case 0x00:
switch (FUNCT3) {
最后,
format Load {
0x2: lw({{ # if QU # if FUNCT3 == 0x02 then declare lw instruction
Rd_sd = Mem_sw;
}});
}
变成
case 0x2:
// Load::lw(['\n Rd_sd = Mem_sw;\n '],{})
return new Lw(machInst);
break;
完整的翻译是:
using namespace gem5;
StaticInstPtr RiscvISA::Decoder::decodeInst(RiscvISA::ExtMachInst machInst) {
using namespace RiscvISAInst;
switch (QUADRANT) { case 0x3:
switch (OPCODE5) { case 0x0:
switch(FUNCT3) {
case 0x2:
// Load::lw(['Rd_sd = Mem_sw;'],{})
return new Lw(machInst);
break;
}
}
}
}
生成的执行 LW 指令的函数
setRegIdxArrays(
reinterpret_cast<RegIdArrayPtr>(
&std::remove_pointer_t<decltype(this)>::srcRegIdxArr),
reinterpret_cast<RegIdArrayPtr>(
&std::remove_pointer_t<decltype(this)>::destRegIdxArr));
;
setDestRegIdx(_numDestRegs++, ((RD) == 0) ? RegId() : intRegClass[RD]);
_numTypedDestRegs[intRegClass.type()]++;
setSrcRegIdx(_numSrcRegs++, ((RS1) == 0) ? RegId() : intRegClass[RS1]);
flags[IsInteger] = true;
flags[IsLoad] = true;
memAccessFlags = MMU::WordAlign;;
offset = sext<12>(IMM12);;
如果你转到 “src/arch/riscv/isa/formats/mem.isa” 中 Load 的声明,你可以弄清楚这是如何构造的:
def format Load(memacc_code, ea_code = {{EA = rvZext(Rs1 + offset);}},
offset_code={{offset = sext<12>(IMM12);}},
mem_flags=[], inst_flags=[]) {{
(header_output, decoder_output, decode_block, exec_output) = \
LoadStoreBase(name, Name, offset_code, ea_code, memacc_code, mem_flags,
inst_flags, 'Load', exec_template_base='Load')
}};
你可以通过这个来了解这个构造函数是如何生成的,但这有点像一个兔子洞。
从 “decoder-ns.hh.inc” 中,你可以看到为 Lw 指令生成的类定义:
class Lw : public Load
{
private:
RegId srcRegIdxArr[1]; RegId destRegIdxArr[1];
public:
/// Constructor.
Lw(ExtMachInst machInst);
Fault execute(ExecContext *, trace::InstRecord *) const override;
Fault initiateAcc(ExecContext *, trace::InstRecord *) const override;
Fault completeAcc(PacketPtr, ExecContext *,
trace::InstRecord *) const override;
};
你可以继续探索
如前所述,ISA 定义是一个兔子洞,可能难以理解。
模板很复杂,通常建立在其他模板和 isa_parser.py 脚本中的专门翻译代码之上。
通过分析 ISA 定义和 isa_parser.py 脚本,你可以更好地理解 ISA 是如何定义的,以及指令是如何被解码和执行的。
生成的 CPP 代码可以通过与 ISA 定义进行比较来理解。
在 GDB 中使用断点来跟踪 gem5 中指令的执行是理解生成的代码如何用于解码和执行指令的好方法。
练习:实现 ADD16 指令
在这个练习中,你将在 gem5 RISC-V ISA 中实现 ADD16。
ADD16 指令是一条 16 位加法指令,它将两个 16 位值相加并将结果存储在 16 位寄存器中。
格式:
| 31 -- 25 | 24 -- 20 | 19 -- 15 | 14 -- 12 | 11 -- 7 | 6 -- 0 |
| 0100000 | rs2 | rs1 | 000 | rd | 0110011 |
| funct7 | | | funct3 | | opcode |
1 -- 0 (`11`) is the quadrant field.
语法:
ADD16, Rs1, Rs2
目的:并行执行 16 位整数元素加法。
描述:这条指令将 Rs1 中的 16 位整数元素与 Rs2 中的 16 位整数元素相加,然后将 16 位元素写入 Rd 寄存器。
让我们运行 materials/03-Developing-gem5-models/05-modeling-cores/02-add16-instruction
这个文件运行 add16_test.c 的二进制文件。这是一个执行 add 16 指令的 C 程序。
我们还没有在 gem5 中实现这条指令。让我们运行这个脚本来查看输出。
add16_test.c 的重要部分
让我们看看 add16_test.c 文件做了什么。
uint64_t num1 = 0xFFFFFFFFFFFFFFFF, num2 = 0xFFFFFFFFFFFFFFFF, output = 0;
printf("RISC-V Packed Addition using 0xFFFFFFFFFFFFFFFF and 0xFFFFFFFFFFFFFFFF \n");
asm volatile("add16 %0, %1,%2\n":"=r"(output):"r"(num1),"r"(num2):);
printf("Output is 0x%LX \n", output);
if (output == 0xFFFEFFFEFFFEFFFE) {
printf("Test Passed! \n");
}
上面的代码片段将两个数字设置为 -1,然后我们运行 ADD16 指令。
我们测试指令运行后输出是否为 -2,并打印结果。
如我们所见,当我们运行
gem5 ./add16_test.py
时,我们得到一个未知指令错误
src/arch/riscv/faults.cc:204: panic: Unknown instruction 0x4000010040e787f7 at pc (0x10636=>0x1063a).(0=>1)
Memory Usage: 1285988 KBytes
Program aborted at tick 18616032
--- BEGIN LIBC BACKTRACE ---
尝试自己将 ADD16 指令实现到 gem5 中。
当遇到困难时,最好的建议是找到类似的指令并尝试理解它们的工作原理。
可以找到帮助你入门的资源在 materials/03-Developing-gem5-models/05-modeling-cores/02-add16-instruction。 值得注意的是,这包含一个编译了 ADD16 指令的二进制文件,以及一个在 RISC-V 系统中运行二进制文件的配置文件。 这个配置会让你知道你是否正确实现了指令。
使用格式指定解码器
让我们反向工作,指定指令格式中的每个位域。
| 31 -- 25 | 24 -- 20 | 19 -- 15 | 14 -- 12 | 11 -- 7 | 6 -- 0 |
| 0100000 | rs2 | rs1 | 000 | rd | 0110011 |
| funct7 | | | funct3 | | opcode |
- quadrant: 0x3
- opcode5: 0x1d
- funct3: 0x0
- funct7: 0x20
由此,我们可以在 ISA 定义中指定解码器:
decode QUADRANT default Unknown::unknown() {
0x3 : decode OPCODE5 {
0x1d: decode FUNCT3 {
format ROp {
0x0: decode FUNCT7 {
0x20: // Add the ADD16 instruction here
}
}
}
}
}
注意:ROp 格式用于寄存器-寄存器操作。
我为你找出了要使用的格式,但你可以在 ISA 定义中找到这个。
接下来,让我们将其添加到 RISC-V “decoder.isa” 文件中。
让我们在 decoder.isa 的第 2057 行添加这个
需要注意的是,此文件中已经定义了其他共享相同 QUADRANT 和 OPCODE5 值的指令。因此,我们只需要插入:
0x1d: decode FUNCT3 {
format ROp {
0x0: decode FUNCT7 {
0x20:
到正确的位置。
接下来让我们添加指令名称:
0x20: add16({{
}});
花括号之间的空间是声明指令行为的地方。
最后我们添加代码。 这只是理解操作并执行适当操作的问题。 在我们的例子中,我们尽可能保持与 CPP 接近。
0x20: add16({{
uint16_t Rd_16 = (uint16_t)(Rs1_ud) +
(uint16_t)(Rs2_ud);
uint16_t Rd_32 = (uint16_t)((Rs1_ud >> 16) +
(Rs2_ud >> 16));
uint16_t Rd_48 = (uint16_t)((Rs1_ud >> 32) +
(Rs2_ud >> 32));
uint16_t Rd_64 = (uint16_t)((Rs1_ud >> 48) +
(Rs2_ud >> 48));
uint64_t result = Rd_64;
result = result << 16 | Rd_48;
result = result << 16 | Rd_32;
result = result << 16 | Rd_16;
Rd = result;
}});
现在让我们再次运行 materials/03-Developing-gem5-models/05-modeling-cores/02-add16-instruction/add16_test.py 脚本并查看输出。
首先,让我们使用我们的更改构建 gem5。
在 gem5 目录中,执行以下命令
scons build/RISCV/gem5.opt -j 8
现在让我们运行 add16_test.py 脚本
../../https://github.com/gem5/gem5/blob/stable/build/RISCV/gem5.opt ./add16_test.py
如我们所见,测试通过了
src/sim/syscall_emul.cc:74: warn: ignoring syscall mprotect(...)
RISC-V Packed Addition using 0xFFFFFFFFFFFFFFFF and 0xFFFFFFFFFFFFFFFF
Output is 0xFFFEFFFEFFFEFFFE
Test Passed!