
在 gem5 中建模缓存
gem5 中的缓存层次结构
gem5 中的主要组件类型之一是缓存层次结构。
在标准库中,缓存层次结构一侧是 Processor(具有多个核心),另一侧是 Memory。
核心和缓存之间(以及内存控制器和缓存之间)是 Ports。
Ports 允许 gem5 中的模型相互发送 Packets(更多信息请参见 在 gem5 中建模内存对象:Ports)。
###

gem5 中的缓存类型
gem5 中有两种缓存模型:
- Classic Cache:简化、快速,但灵活性较低
- Ruby:详细建模缓存一致性
这是 GEMS(包含 Ruby)和 m5(其缓存模型我们现在称为”classic”缓存)合并的历史遗留问题。
Ruby 是一个高度详细的模型,具有许多不同的一致性协议(使用名为”SLICC”的语言指定) 更多关于 Ruby 的信息请参见 在 gem5 中建模缓存一致性。
Classic 缓存更简单、更快,但灵活性和详细程度较低。一致性协议不可参数化,层次结构和拓扑结构是固定的。
大纲
- 缓存一致性背景
- Simple Cache
- Simple cache 中的一致性协议
- 如何使用 simple cache
- Ruby 缓存
- Ruby 组件
- MESI 两级协议示例
什么是一致性
如果多个核心可以访问数据的多个副本(例如,在多个缓存中),并且至少有一个访问是写操作,则可能出现一致性问题

什么是一致性
如果多个核心可以访问数据的多个副本(例如,在多个缓存中),并且至少有一个访问是写操作,则可能出现一致性问题

什么是一致性
如果多个核心可以访问数据的多个副本(例如,在多个缓存中),并且至少有一个访问是写操作,则可能出现一致性问题
Classic Cache:交叉开关层次结构

Classic Cache:一致性交叉开关
每个交叉开关可以连接 n 个 CPU 侧端口和 m 个内存侧端口。

让我们创建一个三级层次结构,包含私有 L1、私有 L2 和连接到多个内存通道的共享 L3。
步骤 1:声明层次结构
打开 materials/02-Using-gem5/05-cache-hierarchies/three_level.py
构造函数已经提供。
class PrivateL1PrivateL2SharedL3CacheHierarchy(AbstractClassicCacheHierarchy):
def __init__(self, l1d_size, l1i_size, l2_size, l3_size, l1d_assoc=8, l1i_assoc=8, l2_assoc=16, l3_assoc=32):
AbstractClassicCacheHierarchy.__init__(self)
self._l1d_size = l1d_size
self._l1i_size = l1i_size
self._l2_size = l2_size
self._l3_size = l3_size
self._l1d_assoc = l1d_assoc
self._l1i_assoc = l1i_assoc
self._l2_assoc = l2_assoc
self._l3_assoc = l3_assoc
添加内存总线
self.membus = SystemXBar(width=64)
这将用于连接缓存和内存。
我们将其设置为 64 字节宽(与缓存行一样宽),以实现最大带宽。
实现层次结构接口
主板需要能够获取端口以连接到内存。
def get_mem_side_port(self):
return self.membus.mem_side_ports
“cpu_side_port” 用于从主板进行一致性 IO 访问。
def get_cpu_side_port(self):
return self.membus.cpu_side_ports
主要函数是 incorporate_cache,它在 Processor 和 Memory 准备好连接在一起后由主板调用。
def incorporate_cache(self, board):
整合缓存
在 incorporate_cache 函数中,我们将创建缓存并将它们连接在一起。
首先,连接系统端口(用于功能访问)并将内存连接到内存总线。 我们还将根据 L2 交叉开关参数创建 L3 交叉开关。
board.connect_system_port(self.membus.cpu_side_ports)
# Connect the memory system to the memory port on the board.
for _, port in board.get_memory().get_mem_ports():
self.membus.mem_side_ports = port
# Create an L3 crossbar
self.l3_bus = L2XBar()
创建核心集群
由于每个核心将拥有许多私有缓存,让我们创建一个集群。 在这个集群中,我们将创建 L1I/D 和 L2 缓存、L2 交叉开关并连接它们。
def _create_core_cluster(self, core, l3_bus, isa):
cluster = SubSystem()
cluster.l1dcache = L1DCache(size=self._l1d_size, assoc=self._l1d_assoc)
cluster.l1icache = L1ICache(
size=self._l1i_size, assoc=self._l1i_assoc, writeback_clean=False
)
core.connect_icache(cluster.l1icache.cpu_side)
core.connect_dcache(cluster.l1dcache.cpu_side)
cluster.l2cache = L2Cache(size=self._l2_size, assoc=self._l2_assoc)
cluster.l2_bus = L2XBar()
cluster.l1dcache.mem_side = cluster.l2_bus.cpu_side_ports
cluster.l1icache.mem_side = cluster.l2_bus.cpu_side_ports
cluster.l2cache.cpu_side = cluster.l2_bus.mem_side_ports
cluster.l2cache.mem_side = l3_bus.cpu_side_ports
全系统特定内容
您已经获得了一些代码来设置其他缓存、中断等,这些是 x86 和 Arm 全系统仿真所需的。
您现在可以忽略这部分。
cluster.iptw_cache = MMUCache(size="8KiB", writeback_clean=False)
cluster.dptw_cache = MMUCache(size="8KiB", writeback_clean=False)
core.connect_walker_ports(
cluster.iptw_cache.cpu_side, cluster.dptw_cache.cpu_side
)
# Connect the caches to the L2 bus
cluster.iptw_cache.mem_side = cluster.l2_bus.cpu_side_ports
cluster.dptw_cache.mem_side = cluster.l2_bus.cpu_side_ports
if isa == ISA.X86:
int_req_port = self.membus.mem_side_ports
int_resp_port = self.membus.cpu_side_ports
core.connect_interrupt(int_req_port, int_resp_port)
else:
core.connect_interrupt()
return cluster
回到 incorporate_cache
现在我们有了集群,我们可以创建集群了。
self.clusters = [
self._create_core_cluster(
core, self.l3_bus, board.get_processor().get_isa()
)
for core in board.get_processor().get_cores()
]
L3 缓存
对于 L1/L2 缓存,我们使用了标准库中的预配置缓存。对于 L3,我们将创建自己的配置。我们需要指定 Cache 中参数的值。
class L3Cache(Cache):
def __init__(self, size, assoc):
super().__init__()
self.size = size
self.assoc = assoc
self.tag_latency = 20
self.data_latency = 20
self.response_latency = 1
self.mshrs = 20
self.tgts_per_mshr = 12
self.writeback_clean = False
self.clusivity = "mostly_incl"
连接 L3 缓存
现在,我们可以通过将 L3 缓存连接到 L3 交叉开关来完成 incorporate_cache。
self.l3_cache = L3Cache(size=self._l3_size, assoc=self._l3_assoc)
# Connect the L3 cache to the system crossbar and L3 crossbar
self.l3_cache.mem_side = self.membus.cpu_side_ports
self.l3_cache.cpu_side = self.l3_bus.mem_side_ports
if board.has_coherent_io():
self._setup_io_cache(board)
测试我们的缓存层次结构
参见 materials/02-Using-gem5/05-cache-hierarchies/test-cache.py。
运行测试脚本以查看缓存层次结构是否正常工作。
gem5 test-cache.py
这使用线性流量,尽管我们也可以使用上一节中的流量生成器。
您还可以使用缓存层次结构运行真实工作负载。
gem5 run-is.py
这包括全系统模式(使用 x86)和 SE 模式(使用 Arm)。
Classic Cache:参数
- src/mem/cache/Cache.py
- src/mem/cache/cache.cc
- src/mem/cache/noncoherent_cache.cc
参数:
- size(大小)
- associativity(关联度)
- number of miss status handler register (MSHR) entries(未命中状态处理寄存器条目数)
- prefetcher(预取器)
- replacement policy(替换策略)
Ruby
Ruby 缓存
- 一致性控制器
- 缓存 + 接口
- 互连

Ruby

Ruby 组件
- 控制器模型(缓存控制器、目录控制器)
- 控制器拓扑(Mesh、全连接等)
- 网络模型
- 接口(classic 端口)
Ruby 缓存:控制器模型
控制器代码通过 SLICC 编译器”生成”
我们将在 在 gem5 中建模缓存一致性 中看到更多详细信息。
Ruby 缓存:示例
让我们使用 MESI 协议做一个示例,看看使用 Ruby 可以获得哪些新统计信息。
我们将查看并行算法(数组求和)的一些不同实现。
parallel_for (int i=0; i < length; i++) {
*result += array[i];
}
不同实现:朴素方法
三种不同的实现:朴素方法、输出上的伪共享,以及无伪共享的分块方法。
“朴素”实现
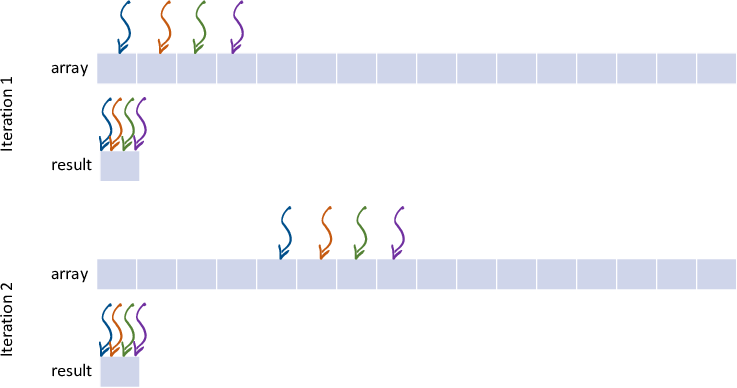
伪共享
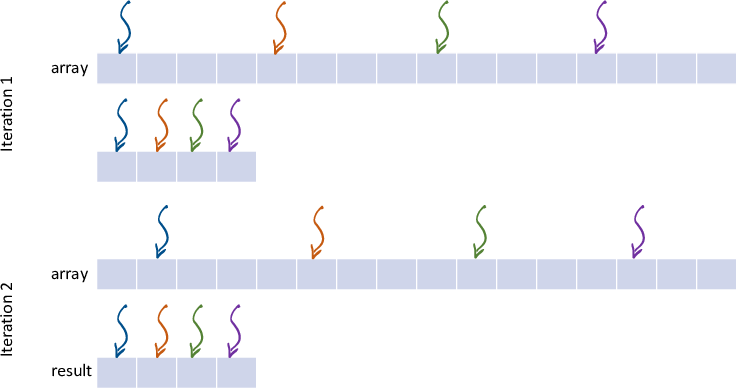
分块和无伪共享
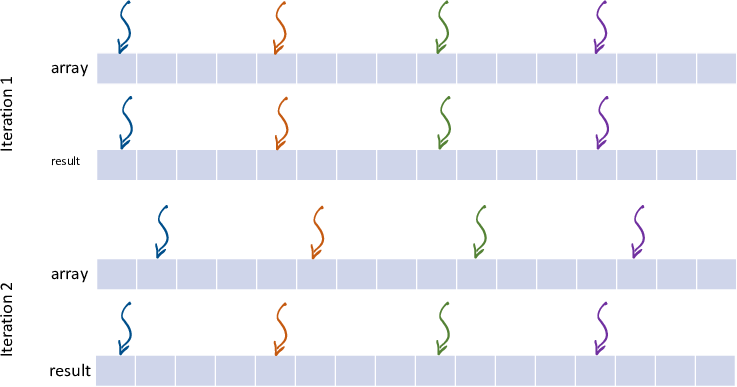
使用 Ruby
我们可以使用 Ruby 来查看这些实现之间缓存行为的差异。
运行脚本 materials/02-Using-gem5/05-cache-hierarchies/ruby-example/run.py。
gem5-mesi --outdir=m5out/naive run.py naive
gem5-mesi --outdir=m5out/false_sharing run.py false_sharing
gem5-mesi --outdir=m5out/chunking run.py chunking
要比较的统计信息
比较以下统计信息:
仿真所花费的时间以及读/写共享
board.cache_hierarchy.ruby_system.L1Cache_Controller.Fwd_GETS:数据被读共享的次数board.cache_hierarchy.ruby_system.L1Cache_Controller.Fwd_GETX:数据被写共享的次数
(注意:对于这些统计信息,忽略数组中的第一项。说来话长…)
我们将在 在 gem5 中建模缓存一致性 中介绍更多关于如何配置 Ruby 的内容。
总结
- 缓存层次结构是 gem5 的关键部分
- Classic 缓存更简单、更快
- Classic 缓存配置和使用简单直接
- Ruby 缓存更详细,可以建模缓存一致性
- 我们可以使用 Ruby 来比较不同的缓存行为