使用 gem5 进行采样模拟
如果 ROI 很大怎么办
我们现在知道如何跳过模拟中”不重要”的部分,但如果模拟中重要的部分太大怎么办?
如果我们面对的不是这种情况

而是实际上面对这种情况

采样
什么是采样?
采样主要有两种类型:
- 目标采样(Targeted sampling)
- 统计采样(Statistical sampling)
目标采样
代表性方法:SimPoint、LoopPoint
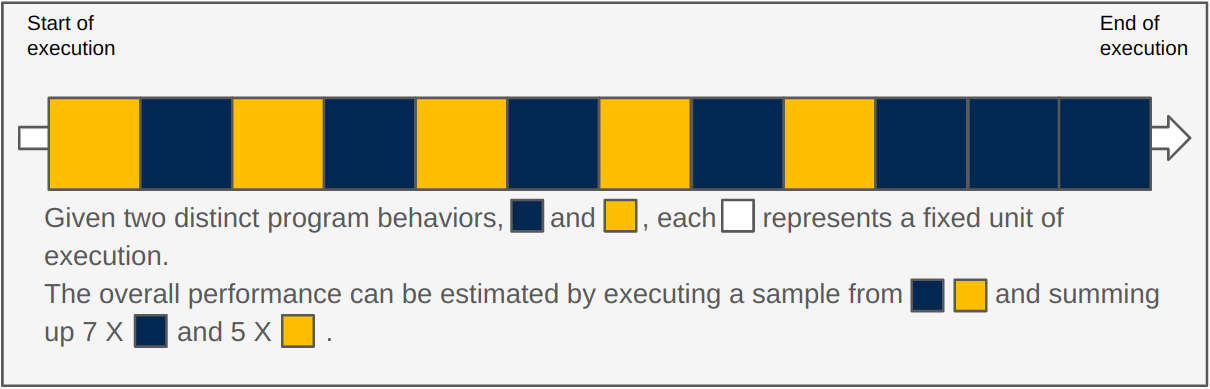
目标采样根据分析发现的特定特征来选择样本。
关于目标采样的更多信息
使用目标采样方法的知名模拟采样方法包括 SimPoint 和 LoopPoint。
这两种方法都将整个程序执行划分为多个区域,每个区域执行固定数量的指令。
它们使用基本块向量,这是执行区域内基本块执行模式的记录。基本块向量可以用作该区域程序行为的特征。下面是一个基本块向量的示例。

它们使用基本块向量进行聚类并找到代表性区域。它们通过仅收集代表性区域的性能并加权求和来预测程序的整体性能。
统计采样
代表性方法:SMARTS、FSA

统计采样,顾名思义,以统计方式选择其采样单元。
关于统计采样的更多信息
统计采样中的代表性模拟采样方法包括 SMARTS 和 FSA。
这两种方法在整个程序执行过程中定期或随机地对少量执行进行详细模拟,并在详细模拟之间进行快进。
它们使用随机分布样本的性能来预测整个程序执行的总体性能。
应用这些技术前我们应该了解什么
无论工具或技术多么优秀,误用都可能是危险的
在使用任何采样技术之前,我们需要确保该采样技术适用于我们的实验。
例如,SimPoint 仅设计用于单线程工作负载,因此如果我们的实验需要多线程工作负载,我们不应该对它们使用 SimPoint。

gem5 提供的功能
在 gem5 中,我们提供了以下基础设施:
Targeted Sampling in gem5
gem5 中的目标采样
- gem5 为 SimPoint 和 LoopPoint 提供基础设施,用于分析程序、为代表区域创建检查点并运行代表区域。 请注意,LoopPoint 分析支持目前在 gem5 v24.0 中不受支持,但已测试并准备在 gem5 v24.1 中上游。
- gem5 还为在 SE 模式下执行 ELFies 提供基础设施,但 gem5 不支持创建 ELFie 文件和权重信息。
SimPoint in gem5
SimPoint
如前所述,使用 SimPoint 有三个步骤:
- 分析
- 创建检查点
- 运行区域
在 gem5 中使用 SimPoint 有两个关键文件:
我们将在本节中看到它们。
SimPoint 分析
在 gem5 中,我们使用 SimPoint 探针监听器对象来收集 SimPoint 聚类区域所需的信息。
该对象定义在 src/cpu/simple/probes/SimPoint.py 中。
SimPoint 探针监听器有两个参数:interval 和 profile_file。
interval接受一个长度作为我们对区域的定义。这意味着每次我们执行n条指令时,我们将其视为一个区域的结束。默认长度为 100,000,000。profile_file接受输出 zip 文件的名称。默认名称是simpoint.bb.gz。
为了使用此探针监听器对象,我们需要将其附加到 ATOMIC CPU。它将在模拟开始时立即开始收集信息,并在模拟结束时停止。 退出模拟后,在模拟输出目录下会有一个包含每个区域基本块向量信息的 zip 文件。
实践时间!
01-simpoint
所有材料可以在 materials/02-Using-gem5/09-sampling/01-simpoint 下找到。完整版本在 materials/02-Using-gem5/09-sampling/01-simpoint/complete 下。 在本练习中,我们只运行脚本而不修改它们。 我们只使用 materials/02-Using-gem5/09-sampling/01-simpoint/simpoint-analysis.py 和 materials/02-Using-gem5/09-sampling/01-simpoint/simpoint3.2-cmd.sh。
目标
- 运行 SimPoint 分析
- 处理数据以获得代表性区域及其权重
01-simpoint
由于性能分析和获取基线性能可能需要一些时间,我们将首先使用以下命令运行模拟。
gem5 -re --outdir=full-detailed-run-m5out full-detailed-run.py
gem5 -re --outdir=simpoint-analysis-m5out simpoint-analysis.py
在本练习中,我们尝试为一个简单的工作负载创建 SimPoints。 简单工作负载的源代码可以在 materials/02-Using-gem5/09-sampling/01-simpoint/workload/simple_workload.c 找到。
这个简单的工作负载分配一个包含一千个 64 位元素的数组,为每个元素分配一个数字,然后通过一千次迭代将它们全部求和。 我们可以预期这个工作负载的程序行为会非常重复。
01-simpoint
脚本 materials/02-Using-gem5/09-sampling/01-simpoint/simpoint-analysis.py 使用我们之前介绍的 SimPoint 探针监听器对象来收集这个简单工作负载的基本块信息。
它使用以下方式将 ATOMIC CPU 核心连接到 SimPoint 探针监听器:
processor.get_cores()[0].core.addSimPointProbe(1_000_000)
这个 addSimPointProbe() 函数的定义可以在 src/cpu/simple/BaseAtomicSimpleCPU.py 下找到。
在这个例子中,我们将 interval_length 设置为 1,000,000,这意味着我们将一个区域定义为执行(提交)了 1,000,000 条指令。
01-simpoint
模拟完成后,我们将在 simpoint-analysis-m5out 文件夹下看到一个名为 simpoint.bb.gz 的 zip 文件。
我们可以使用以下命令解压它:
gzip -d -k simpoint.bb.gz
解压后,我们可以查看 simpoint.bb 文件。
该文件包含简单工作负载的所有基本块向量信息。
在这个工作负载中发现了 9 个区域。
每个区域都有一个基本块向量,以 T 开头。
01-simpoint
正如我们所看到的,区域 2 到 9 具有几乎相同的基本块向量。
T:1900:222 :1901:222 :1902:999216 :1903:333
T:1900:222 :1901:222 :1902:999225 :1903:333
T:1900:222 :1901:222 :1902:999225 :1903:333
T:1900:222 :1901:222 :1902:999225 :1903:333
T:1900:222 :1901:222 :1902:999216 :1903:333
T:1900:222 :1901:222 :1902:999225 :1903:333
T:1900:222 :1901:222 :1902:999225 :1903:333
T:1900:222 :1901:222 :1902:999225 :1903:333
相似的基本块向量表明区域 2 到 9 的程序行为非常相似。因此,我们可以预期将区域 2 到 9 聚类在一起,并从中选择一个区域作为我们的代表区域。该区域将代表从区域 2 到区域 9 的所有区域的性能。
01-simpoint
让我们进一步理解这一行的含义。
T:1900:222 :1901:222 :1902:999216 :1903:333
T表示区域基本块向量的开始。:1900:222表示基本块 1900 执行(提交)了 222 条指令。这里的关键是,222 不是基本块执行的次数,而是基本块执行的次数乘以基本块中的总指令数。如果我们将所有基本块执行的指令相加,我们将大致得到区域的长度。$222+222+999216+333=999993$。
下一步是使用这些信息对区域进行聚类并找到代表性区域。
有很多方法可以做到这一点。在本练习中,我们将使用 SimPoint 论文作者提供的 SimPoint3.2 工具。工具的链接。
01-simpoint
该工具已在 materials/02-Using-gem5/09-sampling/01-simpoint/simpoint 下编译。 我们还在 materials/02-Using-gem5/09-sampling/01-simpoint/simpoint3.2-cmd.sh 中提供了一个包含以下命令的运行脚本。
/workspaces/2024/materials/02-Using-gem5/09-sampling/01-simpoint/simpoint \
-inputVectorsGzipped -loadFVFile simpoint-analysis-m5out/simpoint.bb.gz -k 5 -saveSimpoints \
results.simpts -saveSimpointWeights results.weights
让我们看看这个命令。
它将 simpoint.bb.gz 传递给工具。
它使用 -k 5 将期望的聚类数设置为 5。
它将 SimPoint 信息保存在 results.simpts 中,将它们的权重保存在 results.weight 中。
01-simpoint
使用 ./simpoint3.2-cmd.sh 运行命令后,我们将看到以下内容。
#results.simpts # results.weights
2 0 0.666667 0
1 1 0.222222 1
0 3 0.111111 3
这意味着它在这个程序中找到了 3 个 SimPoints。 区域 2 是 SimPoint 0,权重为 0.666667。 区域 1 是 SimPoint 1,权重为 0.222222。 区域 0 是 SimPoint 3,权重为 0.111111。
没有 5 个聚类是因为算法发现 3 个聚类足以代表所有程序行为。 SimPoint 标签号可能不连续,因为它是聚类的标签号。
SimPoint 检查点
现在我们有了代表性区域及其权重,我们需要找到一种方法来到达这些 SimPoints。
如 08-accelerating-simulation 中介绍,有两种方法可以到达感兴趣的区域。对于 SimPoint,我们通常使用检查点。
要在 gem5 中做到这一点,我们将使用 set_se_simpoint_workoad、SimPoint 类 和 simpoints_save_checkpoint_generator。
实践时间!
01-simpoint
所有材料可以在 materials/02-Using-gem5/09-sampling/01-simpoint 下找到。完整版本在 materials/02-Using-gem5/09-sampling/01-simpoint/complete 下。 我们不会修改任何脚本。
目标
- 使用 SimPoint3.2 工具的输出文件为所有 3 个 SimPoints 创建检查点
因为创建检查点可能需要一些时间,让我们先使用以下命令创建检查点:
gem5 -re --outdir=simpoint-checkpoint-m5out simpoint-checkpoint.py
01-simpoint
让我们看看 materials/02-Using-gem5/09-sampling/01-simpoint/simpoint-checkpoint.py。
有三个关键部分:
# key 1: pass in the representative regions information
from gem5.utils.simpoint import SimPoint
simpoint_info = SimPoint(
simpoint_interval=1_000_000,
simpoint_file_path=Path("/workspaces/2024/materials/02-Using-gem5/09-sampling/01-simpoint/results.simpts"),
weight_file_path=Path("/workspaces/2024/materials/02-Using-gem5/09-sampling/01-simpoint/results.weights"),
warmup_interval=1_000_000
)
# key 2: pass in the SimPoint object to set up the workload
board.set_se_simpoint_workload(
binary=BinaryResource(local_path=Path("/workspaces/2024/materials/02-Using-gem5/09-sampling/01-simpoint/workload/simple_workload").as_posix()),
simpoint=simpoint_info
)
# key 3: register exit event handler to take the checkpoints
simulator = Simulator(
board=board,
on_exit_event={
ExitEvent.SIMPOINT_BEGIN: simpoints_save_checkpoint_generator(dir, simpoint_info)
},
)
01-simpoint
让我们仔细看看 key 1。
from gem5.utils.simpoint import SimPoint
simpoint_info = SimPoint(
simpoint_interval=1_000_000,
simpoint_file_path=Path("/workspaces/2024/materials/02-Using-gem5/09-sampling/01-simpoint/results.simpts"),
weight_file_path=Path("/workspaces/2024/materials/02-Using-gem5/09-sampling/01-simpoint/results.weights"),
warmup_interval=1_000_000
)
simpoint_interval、simpoint_file_path 和 weight_file_path 的参数名称应该是不言自明的,但 warmup_interval 在本节中对我们来说是新的。
如 08-accelerating-simulation 中所述,我们应该预期在恢复检查点时,大多数微架构状态都是冷的。因此,我们需要为感兴趣的区域保留一个预热期,以预热系统的微架构状态。
因此,我们需要在这里设置一个 warmup_interval 值,这样当我们恢复检查点时,我们可以预期有这段长度的模拟来预热我们的微架构状态。
01-simpoint
SimPoint 类还可以检测我们有多少空间用于预热期。如果没有足够的空间,它会自动将该 SimPoint 的预热期缩小到可用空间。例如,如果我们有一个从程序开始处开始的 SimPoint,那么它的预热期应该是 0 条指令。
SimPoint 类还会根据 SimPoints 在指令方面的开始时间自动对它们进行排序。
它还提供可能有用的 getter 函数,例如 get_weight_list(),它返回每个 SimPoint 的权重列表。
更多信息可以在 SimPoint 类定义中找到。
01-simpoint
让我们相信 keys 2 和 3,因为它们都依赖于从 SimPoint 对象传入的信息。
我们可以通过将目标路径作为参数传递给 simpoints_save_checkpoint_generator 来声明我们想要存储 SimPoint 检查点的位置。更多详细信息,我们可以在 src/python/gem5/simulate/exit_event_generators.py 中找到生成器。
01-simpoint
完成检查点创建后,我们应该在 materials/02-Using-gem5/09-sampling/01-simpoint/simpoint-checkpoint 下找到所有 SimPoint 检查点,因为我们将 simpoint-checkpoint 作为保存 SimPoint 检查点的目录传递给 simpoints_save_checkpoint_generator。
应该有三个名为 cpt.SimPoint0、cpt.SimPoint1 和 cpt.SimPoint2 的检查点文件夹。
我们现在可以使用它们来运行简单工作负载的 SimPoints。
运行 SimPoint
现在我们有了代表性 SimPoint 检查点,我们可以使用我们想要测量的系统运行它们,并预测运行整个简单工作负载的整体性能。
SimPoint 依赖于我们从分析阶段获得的权重来进行预测。 权重通过以下公式计算:
\[\text{聚类 } i \text{ 的权重} = \frac{\text{聚类 } i \text{ 中的区域数}}{\text{工作负载执行中的区域总数}}\]例如,如果我们想计算预测的 IPC,我们应该使用: \(\text{预测的 IPC} = \sum_{i=1}^{n} (\text{聚类 } i \text{ 的权重} \times \text{聚类 } i \text{ 的 IPC})\)
01-simpoint
所有材料可以在 materials/02-Using-gem5/09-sampling/01-simpoint 下找到。完整版本在 materials/02-Using-gem5/09-sampling/01-simpoint/complete 下。 我们仍然不会修改任何脚本。
与我们用于 SimPoint 分析和 SimPoint 检查点的简单系统不同,我们现在需要使用我们实际想要测量性能的系统。
我们将使用 materials/02-Using-gem5/09-sampling/01-simpoint/simpoint-run.py 来运行我们的 SimPoints。 对于我们的基线,我们使用 materials/02-Using-gem5/09-sampling/01-simpoint/full-detailed-run.py,它使用详细系统运行整个简单工作负载。
由于时间限制,让我们先运行 SimPoints,然后再解释它的工作原理。 我们在 materials/02-Using-gem5/09-sampling/01-simpoint/run-all-simpoint.sh 中提供了一个运行脚本来运行所有三个
./run-all-simpoint.sh
01-simpoint
让我们看看 materials/02-Using-gem5/09-sampling/01-simpoint/simpoint-run.py。它有一个详细系统,与我们基线中使用的 materials/02-Using-gem5/09-sampling/01-simpoint/full-detailed-run.py 相匹配。
有几个关键点我们想要查看。让我们从我们熟悉的部分开始。
# key 1:
from gem5.utils.simpoint import SimPoint
simpoint_info = SimPoint(
simpoint_interval=1_000_000,
simpoint_file_path=Path("/workspaces/2024/materials/02-Using-gem5/09-sampling/01-simpoint/results.simpts"),
weight_file_path=Path("/workspaces/2024/materials/02-Using-gem5/09-sampling/01-simpoint/results.weights"),
warmup_interval=1_000_000
)
# key 2:
board.set_se_simpoint_workload(
binary=BinaryResource(local_path=Path("/workspaces/2024/materials/02-Using-gem5/09-sampling/01-simpoint/workload/simple_workload").as_posix()),
simpoint=simpoint_info,
checkpoint=Path(f"simpoint-checkpoint/cpt.SimPoint{args.sid}")
)
在这里,我们传入 SimPoint 信息并使用它来设置一个工作负载,该工作负载使用我们的目标 SimPoint id 恢复检查点。
01-simpoint
# key 3:
def max_inst():
warmed_up = False
while True:
if warmed_up:
print("end of SimPoint interval")
yield True
else:
print("end of warmup, starting to simulate SimPoint")
warmed_up = True
# Schedule a MAX_INSTS exit event during the simulation
simulator.schedule_max_insts(
board.get_simpoint().get_simpoint_interval()
)
m5.stats.dump()
m5.stats.reset()
yield False
simulator = Simulator(
board=board,
on_exit_event={ExitEvent.MAX_INSTS: max_inst()},
)
这是我们定义的用于处理预热期和详细模拟期的退出事件处理器。 它在预热期后为 SimPoint 安排结束时间。它还转储并重置统计信息以进行详细测量。
01-simpoint
# key 4:
warmup_interval = board.get_simpoint().get_warmup_list()[args.sid]
if warmup_interval == 0:
warmup_interval = 1
print(f"Starting Simulation with warmup interval {warmup_interval}")
simulator.schedule_max_insts(warmup_interval)
simulator.run()
print("Simulation Done")
print(f"Ran SimPoint {args.sid} with weight {board.get_simpoint().get_weight_list()[args.sid]}")
在开始模拟之前,我们需要设置一个退出事件来指示预热期的结束。
我们使用 simulator.schedule_max_insts() 函数来做到这一点。
我们可以使用 SimPoint 对象的 get_warmup_list() 来获取每个 SimPoint 的预热期长度。
这是 simulator.schedule_max_insts() 函数的一个限制。如果它得到值 0,则不会安排任何退出事件,因此如果预热期长度为 0,我们必须将其设置为 1。
01-simpoint
设置上述键后,脚本就可以运行 SimPoint 了。请注意,每次模拟只能运行一个 SimPoint。
运行 SimPoints 后,我们应该看到输出文件夹 simpoint0-run、simpoint1-run 和 simpoint2-run。
此外,我们应该在 full-detailed-run-m5out 中有基线输出。
让我们尝试使用 SimPoints 的性能来预测整体 IPC!
我们在 materials/02-Using-gem5/09-sampling/01-simpoint/predict_overall_ipc.py 中准备了一个 Python 脚本来进行预测。
我们可以使用以下命令运行它:
python3 predict_overall_ipc.py
01-simpoint
我们应该看到类似这样的内容
predicted IPC: 1.2577933618669999
actual IPC: 1.247741
relative error: 0.8056449108428648%
Python 脚本从我们的基线读取 IPC。 它还从所有 SimPoints 的统计文件中读取详细模拟期的 IPC。 然后它使用以下计算:
predicted_ipc = 0.0
for i in range(num_simpoints):
predicted_ipc += simpoint_ipcs[i] * simpoint_weights[i]
正如输出所示,预测的 IPC 和实际基线 IPC 之间的相对误差约为 0.81%。
SimPoint 总结
恭喜!我们完成了使用 SimPoint 方法进行采样的整个过程。
让我们回顾一下我们所做的:
- 分析程序
- 为代表区域创建检查点
- 运行区域并预测性能
好消息:对于目标采样中的大多数方法,这个过程非常相似。 因此,如果我们知道如何使用 SimPoint 方法进行采样,那么使用其他方法(例如支持多线程工作负载采样的 LoopPoint)应该不会太难。
LoopPoint and ELFies in gem5
LoopPoint 和 ELFies
LoopPoint 与 SimPoint 相似,但有一些关键差异。
LoopPoint 使用循环执行的次数来标记区域,而不是使用执行的指令数。 因此,除了基本块执行信息外,我们还需要在分析阶段收集循环执行信息。 除此之外,它在过程方面与 SimPoint 非常相似(我们在 01-simpoint 中做的 3 步过程)。
LoopPoint 和 ELFies
ELFies 是一种检查点方法,它从大型工作负载执行中创建检查点可执行文件。它可以与 LoopPoint 一起使用来创建代表性区域的可执行文件。
与 LoopPoint 一样,它使用循环执行的次数来标记感兴趣区域的开始和结束,因此我们需要该信息在 gem5 中执行 ELFies。
有关 LoopPoint 和 ELFies 的更多信息,请参见链接。
ELFies
gem5 不生成 ELFies,但我们支持在 SE 模式下运行 ELFies。 所有权重和循环信息应该随 ELFies 工作负载一起提供。
我们可以使用 ELFieInfo 类 运行 ELFies。
在 materials/02-Using-gem5/09-sampling/02-elfies/run-elfies.py 中有一个示例。
我们可以使用以下命令运行它,但不建议这样做,因为它会花费太长时间。
gem5 -re run-elfies.py
这是一个 8 线程实验,使用详细系统,可能运行八亿条指令,因此需要一些时间才能完成。 如果您有兴趣查看输出,我们在 materials/02-Using-gem5/09-sampling/02-elfies/complete/m5out 下有一个完整的 m5out。
ELFies 示例
我们在 gem5 资源中提供了一些 ELFie 工作负载,例如 wrf-s.1_globalr13。其标记(循环执行)信息可以在 elfie-info-wrf-s.1_globalr13 中找到。
我们可以将 ELFies 工作负载设置为普通可执行文件。
board.set_se_binary_workload(
binary=obtain_resource("wrf-s.1_globalr13")
)
然后,我们可以使用以下方式设置开始和结束标记:
from gem5.resources.elfie import ELFieInfo
elfie = ELFieInfo(start = PcCountPair(int("0x100b643",0),1), end = PcCountPair(int("0x526730",0),297879) )
elfie.setup_processor(
processor = processor
)
ELFies 示例
到达开始和结束标记后,模拟器将引发一个 SIMPOINT_BEGIN 退出事件。但是,没有默认的退出事件处理器,因此我们需要定义自己的处理器。
def start_end_handler():
# This is a generator to handle exit event produced by the
# start marker and end marker.
# When we reach the start marker, we reset the stats and
# continue the simulation.
print(f"reached {targets[0]}\n")
print("now reset stats\n")
m5.stats.reset()
print("fall back to simulation\n")
yield False
# When we reach the end marker, we dump the stats to the stats file
# and exit the simulation.
print(f"reached {targets[1]}\n")
print("now dump stats and exit simulation\n")
m5.stats.dump()
yield True
simulator = Simulator(
board=board,
on_exit_event={
ExitEvent.SIMPOINT_BEGIN : start_end_handler()
}
)
LoopPoint 和 ELFies 总结
完成宏基准测试的所有 ELFies 运行后,我们可以使用 ELFie 文件提供的权重来预测整体性能,就像我们在 SimPoint 示例中所做的那样。
现在我们已经涵盖了 gem5 中支持的所有目标采样方法,让我们深入了解统计采样!
Statistical Sampling in gem5
SMARTS
SMARTS 是统计采样方法之一。
它使用统计模型通过随机或定期选择的样本来预测整体性能。 我们使用分布在整个程序执行过程中的小样本来预测平均性能。我们还可以使用平均性能来预测整体性能,例如运行时间。
在运行模拟之前,我们需要确定几个统计参数。
n:样本数量。这是一个计数。k:系统采样间隔。这是一个计数。U:采样单元大小。这是要执行的指令数。W:详细预热期的长度。这是要执行的指令数。
实践时间
03-SMARTS
所有材料可以在 materials/02-Using-gem5/09-sampling/03-SMARTS 下找到。完整版本在 materials/02-Using-gem5/09-sampling/03-SMARTS/complete 下。 我们不会修改任何脚本。
materials/02-Using-gem5/09-sampling/03-SMARTS/SMARTS.py 是一个如何使用退出事件处理器执行 SMARTS 的示例。
我们可以使用以下命令运行它:
gem5 -re SMARTS.py
此脚本将在来自 01-simpoint 的工作负载上使用 SMARTS,因此我们可以使用来自 materials/02-Using-gem5/09-sampling/01-simpoint/full-detailed-run.py 的基线性能来验证我们使用 SMARTS 预测的性能。
03-SMARTS
让我们看看带有统计参数的 smarts_generator。
n:样本数量。这是一个计数。-
k:系统采样间隔。这是一个计数。 U:采样单元大小。这是执行的指令数。W:详细预热期的长度。这是执行的指令数。

03-SMARTS
为了确定 k 和 W,我们首先需要确定理想的 n。
在 SMARTS 论文中,他们将大样本量定义为 $n > 30$。在本练习中,让我们将理想的 n 设置为 50。
设置理想的 n 后,我们可以将其与工作负载中执行的指令一起使用来确定理想的 k。
以下是在 Python 中如何完成的示例。
program_length = 9115640
ideal_region_length = math.ceil(program_length/50)
ideal_U = 1000
ideal_k = math.ceil(ideal_region_length/ideal_U)
ideal_W = 2 * ideal_U
使用这些参数,我们将有大约 50 个样本。每个样本之间的间隔为 $(k-1)*U=182000$ 条指令。每个样本在详细测量中有 1000 条指令,预热期有 2000 条指令。
03-SMARTS
此 SMARTS 退出生成器仅适用于 SwitchableProcessor。 当它到达详细预热部分的开始时,它会重置统计信息;然后它切换核心类型并安排预热部分结束和间隔结束。
当它到达详细预热结束时,它会重置统计信息。
当它到达详细模拟结束时,它会转储统计信息;然后它切换核心类型并安排下一个详细预热部分的开始。

03-SMARTS
现在我们了解了 smarts_generator 将做什么,让我们看看我们在 materials/02-Using-gem5/09-sampling/03-SMARTS/SMARTS.py 中使用的系统。
它使用与 materials/02-Using-gem5/09-sampling/01-simpoint/full-detailed-run.py 完全相同的系统,除了它使用 SimpleSwitchableProcessor 在 ATOMIC CPU 和 O3 CPU 之间切换以进行快进和详细模拟。
如果使用以下命令运行模拟:
gem5 -re SMARTS.py
我们可以运行 materials/02-Using-gem5/09-sampling/03-SMARTS/predict_ipc.py 来预测整体 IPC 并计算与基线 IPC 的相对误差。
python3 predict_ipc.py
03-SMARTS
materials/02-Using-gem5/09-sampling/03-SMARTS/predict_ipc.py 所做的是从每个样本读取 IPC,对 IPC 求和,然后除以样本总数来计算程序的平均 IPC。
$\text{平均 IPC} = \frac{\sum_{i=1}^{n} \text{IPC}_i}{n}$
这是我们期望看到的内容:
Number of samples: 50
Predicted Overall IPC: 1.2563117400000001
Actual Overall IPC: 1.247741
Relative Error: 0.6869005667041583%
正如输出所示,预测的 IPC 和实际基线 IPC 之间的相对误差约为 0.69%。
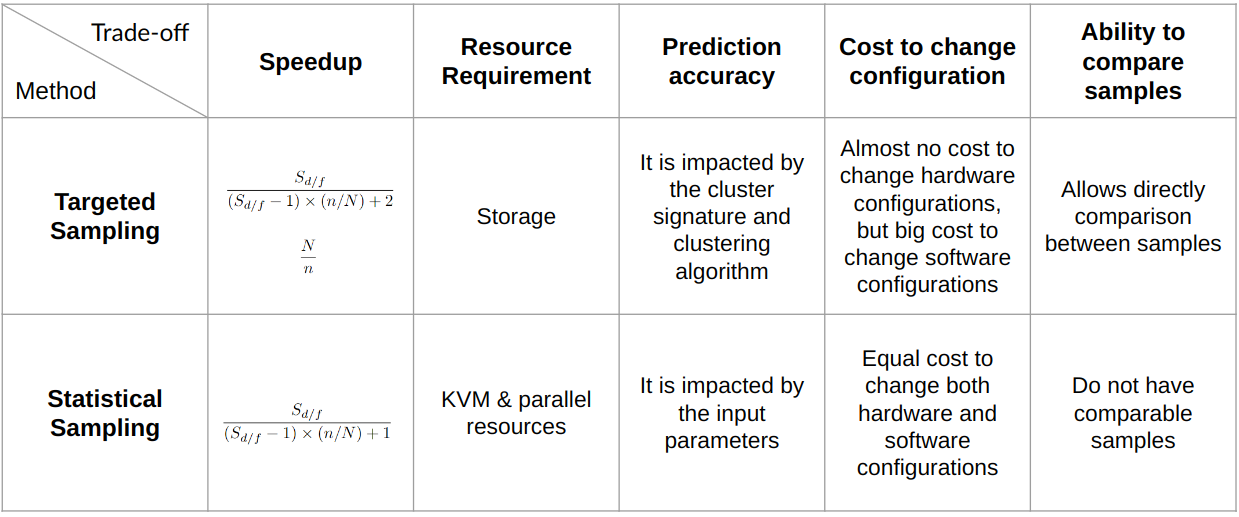
总结
现在我们已经实验了 gem5 中的目标采样和统计采样,让我们以权衡来结束。