
在 gem5 中运行程序
我们将介绍的内容
- 系统调用仿真模式简介
- m5ops
- 注释工作负载
- 交叉编译工作负载
- 流量生成器
系统调用仿真模式简介
什么是系统调用仿真模式,何时使用/避免使用
系统调用仿真(SE)模式不会模拟系统中的所有设备。它专注于模拟 CPU 和内存系统。它只仿真 Linux 系统调用,并且只模拟用户模式代码。
当实验不需要模拟操作系统(例如页表遍历)、不需要高保真度模型(仿真即可),并且需要更快的仿真速度时,SE 模式是一个不错的选择。
但是,如果实验需要模拟操作系统交互,或者需要高保真度地模拟系统,那么我们应该使用全系统(FS)模式。FS 模式将在 07-full-system 中介绍。
示例
00-SE-hello-world
在 materials/02-Using-gem5/03-running-in-gem5/00-SE-hello-world 目录下,有一个 SE 仿真的小例子。
00-SE-hello-world.py 将使用简单的 X86 配置运行 00-SE-hello-world 二进制文件。
这个二进制文件会打印字符串 Hello, World!。
如果我们使用调试标志 SyscallAll,我们将能够看到模拟了哪些系统调用。
我们可以使用以下命令来执行:
gem5 -re --debug-flags=SyscallAll 00-SE-hello-world.py
-re是--stdout-file和--stderr-file的别名,用于将输出重定向到文件。 默认输出在m5out/simout.txt和 m5out/simerr.txt` 中。
00-SE-hello-world
然后在 simout.txt 中,我们应该看到:
280945000: board.processor.cores.core: T0 : syscall Calling write(1, 21152, 14)...
Hello, World!
280945000: board.processor.cores.core: T0 : syscall Returned 14.
左侧是仿真的时间戳。 正如时间戳所示,SE 仿真不会记录系统调用的时间。
注意,在
simout.txt文件中,来自仿真器和客户机的标准输出混合在一起。
m5ops
什么是 m5ops
- m5ops(m5 操作码的缩写)提供不同的功能,可用于在模拟工作负载和仿真器之间进行通信。
- 常用的功能如下。更多信息可以在 m5ops 文档 中找到:
- exit [delay]: 在延迟纳秒后停止仿真
- workbegin: 触发类型为 “workbegin” 的退出事件,可用于标记 ROI 的开始
- workend: 触发类型为 “workend” 的退出事件,可用于标记 ROI 的结束
- resetstats [delay[period]]: 在延迟纳秒后重置仿真统计信息;每 period 纳秒重复一次
- dumpstats [delay[period]]: 在延迟纳秒后将仿真统计信息保存到文件;每 period 纳秒重复一次
- checkpoint [delay [period]]: 在延迟纳秒后创建检查点;每 period 纳秒重复一次
- switchcpu: 触发类型为 “switch cpu” 的退出事件,允许 Python 根据需要切换到不同的 CPU 模型
重要提示
- 并非所有操作都会自动执行它们所说的功能
- 这些操作中的大多数只是退出仿真
- 例如:
- exit: 实际退出
- workbegin: 仅在
System中配置时才退出 - workend: 仅在
System中配置时才退出 - resetstats: 重置统计信息
- dumpstats: 转储统计信息
- checkpoint: 仅退出
- switchcpu: 仅退出
- 详细信息请参见 gem5/src/sim/pseudo_inst.cc。
- gem5 标准库可能对某些 m5ops 有默认行为。默认行为请参见 src/python/gem5/simulate/simulator.py。
关于 m5ops 的更多信息
m5ops 有三种版本:
- 指令模式:仅适用于模拟的 CPU 模型
- 地址模式:适用于模拟的 CPU 模型和 KVM CPU(仅支持 Arm 和 X86)
- 半主机模式:适用于模拟的 CPU 模型和 Fast Model
应根据 CPU 类型和 ISA 使用不同的模式。
地址模式 m5ops 将在 07-full-system 中作为 gem5-bridge 介绍,并在 08-accelerating-simulation 中介绍 KVM CPU 后讨论。 在本节中,我们只介绍指令模式。
何时使用 m5ops
使用 m5ops 主要有两种方式:
- 注释工作负载
- 在磁盘镜像中进行 gem5-bridge 调用
在本节中,我们将重点学习如何使用 m5ops 来注释工作负载。
如何使用 m5ops
m5ops 提供了一个功能库。所有函数可以在 gem5/include/gem5/m5ops.h 中找到。 常用的函数(它们与上面列出的常用功能对应):
void m5_exit(uint64_t ns_delay)void m5_work_begin(uint64_t workid, uint64_t threadid)void m5_work_end(uint64_t workid, uint64_t threadid)void m5_reset_stats(uint64_t ns_delay, uint64_t ns_period)void m5_dump_stats(uint64_t ns_delay, uint64_t ns_period)void m5_checkpoint(uint64_t ns_delay, uint64_t ns_period)void m5_switch_cpu(void)
为了在工作负载中调用这些函数,我们需要将 m5ops 库链接到工作负载。 所以首先,我们需要构建 m5ops 库。
构建 m5ops 库
m5 工具位于 gem5/util/m5 目录中。 为了构建 m5ops 库,
cd进入gem5/util/m5目录- 运行
scons [{TARGET_ISA}.CROSS_COMPILE={TARGET_ISA CROSS COMPILER}] build/{TARGET_ISA}/out/m5 - 编译后的库(
m5用于命令行工具,libm5.a是 C 库)将位于gem5/util/m5/build/{TARGET_ISA}/out
注意事项
- 如果主机系统 ISA 与目标 ISA 不匹配,那么我们需要使用交叉编译器。
TARGET_ISA必须是小写。
动手实践!
01-build-m5ops-library
让我们为 x86 和 arm64 构建 m5ops 库
cd /workspaces/2024/gem5/util/m5
scons build/x86/out/m5
scons arm64.CROSS_COMPILE=aarch64-linux-gnu- build/arm64/out/m5
注意:虽然我们使用 Scons 来构建这些,但这是一个与使用不同目标和选项构建 gem5 不同的环境。 不要期望它们相似(例如,使用
arm64而不是ARM)。
将 m5ops 库链接到 C/C++ 代码
构建 m5ops 库后,我们可以通过以下方式将它们链接到我们的工作负载:
-
在工作负载的源文件中包含 gem5/m5ops.h (
<gem5/m5ops.h>) -
将 gem5/include 添加到编译器的包含搜索路径中 (
-Igem5/include) -
将 gem5/util/m5/build/{TARGET_ISA}/out 添加到链接器搜索路径中 (
-Lgem5/util/m5/build/{TARGET_ISA}/out) -
使用 (
-lm5) 链接 libm5.a
动手实践!
02-annotate-this
让我们使用 m5_work_begin 和 m5_work_end 来注释工作负载
在 materials/02-Using-gem5/03-running-in-gem5/02-annotate-this 目录中,有一个名为 02-annotate-this.cpp 的工作负载源文件和一个 Makefile。
工作负载主要做两件事:
- 将字符串写入标准输出
write(1, "This will be output to standard out\n", 36);
02-annotate-this
- 输出当前目录中所有文件和文件夹的名称
struct dirent *d;
DIR *dr;
dr = opendir(".");
if (dr!=NULL) {
std::cout<<"List of Files & Folders:\n";
for (d=readdir(dr); d!=NULL; d=readdir(dr)) {
std::cout<<d->d_name<< ", ";
}
closedir(dr);
}
else {
std::cout<<"\nError Occurred!";
}
std::cout<<std::endl;
02-annotate-this
本练习的目标
- 将
write(1, "This will be output to standard out\n", 36);标记为我们的关注区域,以便我们可以看到系统调用的执行跟踪。
我们如何做到这一点?
- 使用
#include <gem5/m5ops.h>包含 m5ops 头文件 - 在
write(1, "This will be output to standard out\n", 36);之前立即调用m5_work_begin(0, 0);。 - 在
write(1, "This will be output to standard out\n", 36);之后立即调用m5_work_end(0, 0); - 使用以下要求编译工作负载:
- 将 gem5/include 添加到编译器的包含搜索路径中
- 将 gem5/util/m5/build/x86/out 添加到链接器搜索路径中
- 链接 libm5.a
02-annotate-this
对于步骤 4,我们可以修改 Makefile 使其运行
$(GXX) -o 02-annotate-this 02-annotate-this.cpp \
-I$(GEM5_PATH)/include \
-L$(GEM5_PATH)/util/m5/build/$(ISA)/out \
-lm5
如果您遇到任何问题,所有内容的完成版本位于 materials/02-Using-gem5/03-running-in-gem5/02-annotate-this/complete。
02-annotate-this
如果工作负载编译成功,我们可以尝试运行它
./02-annotate-this
但是,我们将看到以下错误:
Illegal instruction (core dumped)
这是因为主机无法识别指令版本的 m5ops。
这也是如果我们在仿真中使用 KVM CPU,我们需要使用地址版本的 m5ops 的原因。
动手实践!
03-run-x86-SE
让我们编写一个处理程序来处理 m5 退出事件
首先,让我们看看默认行为是什么。进入文件夹 materials/02-Using-gem5/03-running-in-gem5/03-run-x86-SE 并使用以下命令运行 03-run-x86-SE.py:
gem5 -re 03-run-x86-SE.py
运行仿真后,我们应该在 materials/02-Using-gem5/03-running-in-gem5/03-run-x86-SE 中看到一个名为 m5out 的目录。打开 m5out 中的文件 simerr.txt。我们应该看到如下两行:
warn: No behavior was set by the user for work begin. Default behavior is resetting the stats and continuing.
warn: No behavior was set by the user for work end. Default behavior is dumping the stats and continuing.
03-run-x86-SE
如前所述,gem5 标准库可能对某些 m5ops 有默认行为。在这里,我们可以看到它对 m5_work_begin 和 m5_work_end 有默认行为。
让我们稍微绕一下,看看 gem5 标准库如何识别退出事件并为其分配默认的退出处理程序。
所有标准库定义的退出事件可以在 src/python/gem5/simulate/exit_event.py 中找到。它使用退出事件的退出字符串来对退出事件进行分类。例如,"workbegin" 和 "m5_workend instruction encountered" 退出字符串都被归类为 ExitEvent.WORKBEGIN。
所有预定义的退出事件处理程序可以在 src/python/gem5/simulate/exit_event_generators.py 中找到。
例如,ExitEvent.WORKBEGIN 默认使用 reset_stats_generator。这意味着当我们使用标准库的 Simulator 对象时,如果有退出字符串为 "workbegin" 或 "m5_workbegin instruction encountered" 的退出,它将自动执行 m5.stats.reset(),除非我们使用 gem5 stdlib Simulator 参数中的 on_exit_event 参数覆盖默认行为。
03-run-x86-SE
让我们添加自定义的 workbegin 和 workend 处理程序,并使用 Simulator 参数中的 on_exit_event 参数来覆盖默认行为。为此,将以下内容添加到 03-run-x86-SE.py 中:
# define a workbegin handler
def workbegin_handler():
print("Workbegin handler")
m5.debug.flags["ExecAll"].enable()
yield False
#
# define a workend handler
def workend_handler():
m5.debug.flags["ExecAll"].disable()
yield False
#
###
此外,在 Simulator 对象构造中使用 on_exit_event 参数注册处理程序。
# setup handler for ExitEvent.WORKBEGIN and ExitEvent.WORKEND
on_exit_event= {
ExitEvent.WORKBEGIN: workbegin_handler(),
ExitEvent.WORKEND: workend_handler()
}
#
03-run-x86-SE
让我们使用以下命令再次运行此仿真
gem5 -re 03-run-x86-SE.py
现在,我们将在 materials/02-Using-gem5/03-running-in-gem5/03-run-x86-SE/m5out/simout.txt 中看到以下内容
3757178000: board.processor.cores.core: A0 T0 : 0x7ffff7c82572 @_end+140737350460442 : syscall : IntAlu : flags=()
This will be output to standard out
3757180000: board.processor.cores.core: A0 T0 : 0x7ffff7c82574 @_end+140737350460444 : cmp rax, 0xfffffffffffff000
这显示了我们使用 m5.debug.flags["ExecAll"].enable() 为 ROI 启用的调试标志 ExecAll 的日志。它显示了我们 ROI 的完整执行跟踪。正如左侧的时间戳再次表明的那样,SE 模式不会记录模拟系统调用的时间。此外,正如日志所示,我们覆盖了 m5_work_begin 和 m5_work_end 的默认行为。
然后,通过输出
List of Files & Folders:
., .., 03-run-SE.py, m5out,
Simulation Done
这表明 SE 模式能够读取主机上的文件。此外,SE 模式能够写入主机上的文件。
但是,再次强调,SE 模式不能记录模拟系统调用的时间。
SE 模式提示
使用 gem5 stdlib,我们通常使用 board 对象中的 set_se_binary_workload 函数来设置工作负载。我们可以使用相应的参数将文件、参数、环境变量和输出文件路径传递给 set_se_binary_workload 函数。
def set_se_binary_workload(
self,
binary: BinaryResource,
exit_on_work_items: bool = True,
stdin_file: Optional[FileResource] = None,
stdout_file: Optional[Path] = None,
stderr_file: Optional[Path] = None,
env_list: Optional[List[str]] = None,
arguments: List[str] = [],
checkpoint: Optional[Union[Path, CheckpointResource]] = None,
) -> None:
更多信息,我们可以查看 src/python/gem5/components/boards/se_binary_workload.py。
交叉编译
从一个 ISA 交叉编译到另一个 ISA。
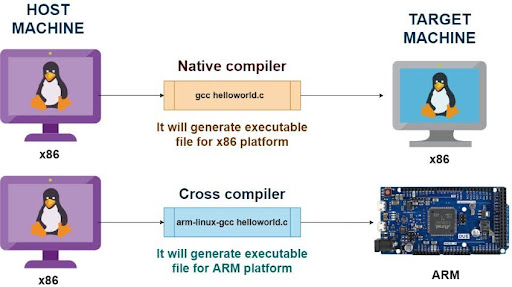
动手实践!
04-cross-compile-workload
让我们将工作负载静态和动态交叉编译到 arm64
对于静态编译,将以下命令添加到 materials/02-Using-gem5/03-running-in-gem5/04-cross-compile-workload 中的 Makefile:
$(GXX) -o 04-cross-compile-this-static 04-cross-compile-this.cpp -static -I$(GEM5_PATH)/include -L$(GEM5_PATH)/util/m5/build/$(ISA)/out -lm5
对于动态编译,添加以下命令:
$(GXX) -o 04-cross-compile-this-dynamic 04-cross-compile-this.cpp -I$(GEM5_PATH)/include -L$(GEM5_PATH)/util/m5/build/$(ISA)/out -lm5
接下来,在与 Makefile 相同的目录中运行 make。
04-cross-compile-workload
注意事项:
注意我们使用 arm64 作为 ISA,使用 aarch64-linux-gnu-g++ 作为交叉编译器。这与练习 2 形成对比,练习 2 中 ISA 是 x86,编译器是 g++。
还要注意,静态编译命令有 -static 标志,而动态命令没有额外的标志。
动手实践!
05-run-arm-SE
让我们运行编译好的 arm64 工作负载,看看会发生什么
首先,让我们运行静态编译的工作负载。cd 进入目录 materials/02-Using-gem5/03-running-in-gem5/05-run-arm-SE 并使用以下命令运行 05-run-arm-SE.py:
gem5 -re --outdir=static 05-run-arm-SE.py --workload-type=static
接下来,让我们使用以下命令运行动态编译的工作负载:
gem5 -re --outdir=dynamic 05-run-arm-SE.py --workload-type=dynamic
05-run-arm-SE
运行动态编译的工作负载时,您将在 dynamic/simout.txt 中看到以下错误输出:
src/base/loader/image_file_data.cc:105: fatal: fatal condition fd < 0 occurred: Failed to open file /lib/ld-linux-aarch64.so.1.
This error typically occurs when the file path specified is incorrect.
Memory Usage: 217652 KBytes
要使用动态编译的工作负载,我们必须重定向库路径。我们可以通过在配置脚本中的 print("Time to redirect the library path") 下添加以下内容来实现:
setInterpDir("/usr/aarch64-linux-gnu/")
board.redirect_paths = [RedirectPath(app_path=f"/lib",
host_paths=[f"/usr/aarch64-linux-gnu/lib"])]
总结
SE 模式不实现很多东西!
- 文件系统
- 大多数系统调用
- I/O 设备
- 中断
- TLB 缺失
- 页表遍历
- 上下文切换
- 多线程
- 您可能有多线程执行,但没有上下文切换和自旋锁
gem5 中的流量生成器
合成流量生成
合成流量生成是一种驱动内存子系统的技术,不需要模拟处理器模型和运行工作负载程序。关于合成流量生成,我们必须注意以下几点。
- 它可以用于以下用途:测量最大理论带宽、测试缓存一致性协议的正确性
- 它不能用于:测量工作负载的执行时间(即使您有它们的内存跟踪)
合成流量可以遵循某些模式,如 sequential (linear)、strided 和 random。在本节中,我们将了解 gem5 中促进合成流量生成的工具。

gem5:用于合成流量生成的标准库组件
gem5 的标准库有一组用于生成合成流量的组件。所有这些组件都继承自 AbstractGenerator,位于 src/python/gem5/components/processors。
- 这些组件模拟内存访问。它们旨在替换您在 gem5 中配置的系统中的处理器。
- 这些组件的示例包括
LinearGenerator和RandomGenerator。
我们将看到如何使用 LinearGenerator 和 RandomGenerator 来刺激内存子系统。我们将使用的内存子系统将包括一个具有 private l1 caches and a shared l2 cache 的缓存层次结构,以及一个 DDR3 内存通道。
在接下来的幻灯片中,我们将从高层次查看 LinearGenerator 和 RandomGenerator。我们将看到如何编写使用它们的配置脚本。
##
LinearGenerator
class LinearGenerator(AbstractGenerator):
def __init__(
self,
num_cores: int = 1,
duration: str = "1ms",
rate: str = "100GB/s",
block_size: int = 64,
min_addr: int = 0,
max_addr: int = 32768,
rd_perc: int = 100,
data_limit: int = 0,
) -> None:
RandomGenerator
class RandomGenerator(AbstractGenerator):
def __init__(
self,
num_cores: int = 1,
duration: str = "1ms",
rate: str = "100GB/s",
block_size: int = 64,
min_addr: int = 0,
max_addr: int = 32768,
rd_perc: int = 100,
data_limit: int = 0,
) -> None:
LinearGenerator/RandomGenerator:参数
- num_cores
- 系统中的核心数
- duration
- 生成流量的时间长度
- rate
- 从内存请求数据的速率
- 注意:这不是内存响应的速率。这是发出请求的最大速率
- 从内存请求数据的速率
- block_size
- 每次读/写访问的字节数
###
- min_addr
- 生成器要访问的最低内存地址(通过读/写)
- max_addr
- 生成器要访问的最高内存地址(通过读/写)
- rd_perc
- 应该是读操作的访问百分比
- data_limit
- 生成器可以访问的最大字节数(通过读/写)
- 注意:如果
data_limit设置为 0,则没有数据限制。
- 注意:如果
- 生成器可以访问的最大字节数(通过读/写)
流量模式可视化
min_addr: 0, max_addr: 4, block_size: 1
Linear(线性):我们想要访问地址 0 到 4,所以线性访问意味着按以下顺序访问内存。
Random(随机):我们想要访问地址 0 到 4,所以随机访问意味着以任何顺序访问内存。(在此示例中,我们显示的顺序是:1, 3, 2, 0)。
###


动手实践!
06-traffic-gen
让我们运行一个关于如何使用流量生成器的示例
打开以下文件。
materials/02-Using-gem5/03-running-in-gem5/06-traffic-gen/simple-traffic-generators.py
步骤:
- 使用线性流量生成器运行。
- 使用混合流量生成器运行。
06-traffic-gen: LinearGenerator:查看代码
转到右侧的代码部分。
现在,我们已经设置了一个具有私有 L1 共享 L2 缓存层次结构的板(转到 materials/02-Using-gem5/03-running-in-gem5/06-traffic-gen/components/cache_hierarchy.py 查看其构造方式),以及一个单通道内存系统。
在 memory = SingleChannelDDR3_1600() 下方立即添加流量生成器,使用以下行。
generator = LinearGenerator(num_cores=1, rate="1GB/s")
###
cache_hierarchy = MyPrivateL1SharedL2CacheHierarchy()
memory = SingleChannelDDR3_1600()
motherboard = TestBoard(
clk_freq="3GHz",
generator=generator,
memory=memory,
cache_hierarchy=cache_hierarchy,
)
06-traffic-gen: LinearGenerator:完成的代码
完成的代码片段应该如下所示。
cache_hierarchy = MyPrivateL1SharedL2CacheHierarchy()
memory = SingleChannelDDR3_1600()
generator = LinearGenerator(num_cores=1, rate="1GB/s")
motherboard = TestBoard(
clk_freq="3GHz",
generator=generator,
memory=memory,
cache_hierarchy=cache_hierarchy,
)
06-traffic-gen: LinearGenerator:运行代码
运行以下命令以查看线性流量生成器的运行情况
cd ./materials/02-Using-gem5/03-running-in-gem5/06-traffic-gen/
gem5 --debug-flags=TrafficGen --debug-end=1000000 \
simple-traffic-generators.py
我们将在下一张幻灯片中看到一些预期的输出。
06-traffic-gen: LinearGenerator 结果
59605: system.processor.cores.generator: LinearGen::getNextPacket: r to addr 0, size 64
59605: system.processor.cores.generator: Next event scheduled at 119210
119210: system.processor.cores.generator: LinearGen::getNextPacket: r to addr 40, size 64
119210: system.processor.cores.generator: Next event scheduled at 178815
178815: system.processor.cores.generator: LinearGen::getNextPacket: r to addr 80, size 64
178815: system.processor.cores.generator: Next event scheduled at 238420
在整个输出中,我们看到 r to addr --。这意味着流量生成器正在模拟访问内存地址 0x-- 的读请求。
在上面,我们在第 1 行看到 r to addr 0,在第 3 行看到 r to addr 40,在第 5 行看到 r to addr 80。
这是因为线性流量生成器正在模拟访问内存地址 0x0000、0x0040、0x0080 的请求。
如您所见,模拟的请求非常线性。每次新的内存访问都比前一次高 0x0040 字节。
06-traffic-gen: Random
我们现在不会这样做,但如果您将 LinearGenerator 替换为 RandomGenerator 并保持参数相同,输出将如下所示。请注意地址模式不再是线性序列。
59605: system.processor.cores.generator: RandomGen::getNextPacket: r to addr 2000, size 64
59605: system.processor.cores.generator: Next event scheduled at 119210
119210: system.processor.cores.generator: RandomGen::getNextPacket: r to addr 7900, size 64
119210: system.processor.cores.generator: Next event scheduled at 178815
178815: system.processor.cores.generator: RandomGen::getNextPacket: r to addr 33c0, size 64
178815: system.processor.cores.generator: Next event scheduled at 238420
我们的重点:LinearGenerator 和 AbstractGenerator
- 我们将重点关注
LinearGenerator和RandomGenerator生成器(稍后还有一个新的!)。- 它们本质上是相同的,但一个执行线性内存访问,另一个执行随机内存访问

详细查看某些组件
- 您可以在
src/python/gem5/components/processors下找到所有与生成器相关的标准库组件。 - 查看
AbstractGenerator.__init__,您会看到此类接受AbstractGeneratorCores列表作为输入。继承自AbstractGenerator的示例类是LinearGenerator和RandomGenerator。 - 我们将查看扩展
AbstractGeneratorCore的类,这些类将通过使用名为PyTrafficGen的SimObject来创建合成流量。更多信息,您可以查看src/cpu/testers/traffic_gen。 LinearGenerator可以有多个LinearGeneratorCores,RandomGenerator可以有多个RandomGeneratorCores。
接下来,我们将查看如何扩展 AbstractGenerator 以创建同时具有 LinearGeneratorCores 和 RandomGeneratorCores 的 HybridGenerator。
扩展 AbstractGenerator
gem5 在其标准库中有很多工具,但如果您想在研究中模拟特定的内存访问模式,标准库中可能没有相应的工具。
在这种情况下,您必须扩展 AbstractGenerator 以创建适合您需求的具体生成器。
为此,我们将通过一个名为 HybridGenerator 的示例来说明。
HybridGenerator 的目标是同时模拟线性和随机内存访问。
为此,我们需要 LinearGeneratorCores(用于模拟线性流量)和 RandomGeneratorCores(用于模拟随机流量)。
06-traffic-gen: HybridGenerator:关于 LinearGeneratorCores 的快速说明
LinearGeneratorCores 模拟线性流量。
当我们有多个 LinearGeneratorCores 时,如果我们将每个都配置为具有相同的 min_addr 和 max_addr,每个都将从相同的 min_addr 开始模拟内存访问,并上升到相同的 max_addr。它们将同时访问相同的地址。
我们希望 LinearGeneratorCore 模拟更合理的访问模式。
因此,我们将让每个 LinearGeneratorCore 模拟对不同内存块的访问。为此,我们必须将内存分割成大小相等的块,并配置每个 LinearGeneratorCore 以模拟对这些块之一的访问。
06-traffic-gen: HybridGenerator:关于 LinearGeneratorCores 的快速说明(续)
这是一个显示每个 LinearGeneratorCore 应该如何访问内存的图表。

06-traffic-gen: HybridGenerator:划分内存地址范围
当我们创建 HybridGenerator 时,我们必须确定哪个 LinearGeneratorCore 获得哪个内存块。
如前所述,我们需要将内存地址范围划分为大小相等的部分,并配置每个 LinearGeneratorCore 以模拟对不同部分的访问。
为了划分,我们将使用 gem5/src/python/gem5/components/processors/abstract_generator.py 中的 partition_range() 函数。
此函数接受 min_addr 到 max_addr 的范围,并将其划分为 num_partitions 个等长的片段。
例如,如果 min_addr = 0,max_addr = 9,num_partitions = 3,那么 partition_range 将返回 <0,3>、<3,6>、<6,9>。
06-traffic-gen: HybridGenerator:关于 RandomGeneratorCores 的快速提醒
我们还必须考虑 RandomGeneratorCores。
假设我们应该像 LinearGeneratorCores 一样对它们进行分区是合理的,但事实并非如此。
即使每个 RandomGeneratorCore 具有相同的 min_addr 和 max_addr,由于每个都模拟随机内存访问,每个都将模拟对不同(随机)内存地址的访问。
06-traffic-gen: HybridGenerator:划分内存地址范围(续)
最后,这就是每个核心将如何模拟内存访问。

06-traffic-gen: HybridGenerator:选择核心分布
既然我们知道每个核心将如何访问内存,接下来,我们需要确定需要多少个 LinearGeneratorCores 和 RandomGeneratorCores。
有很多正确的方法可以做到这一点,但我们将使用以下函数来确定 LinearGeneratorCores 的数量。
def get_num_linear_cores(num_cores: int):
"""
Returns the largest power of two that is smaller than num_cores
"""
if (num_cores & (num_cores - 1) == 0):
return num_cores//2
else:
return 2 ** int(log(num_cores, 2))
其余的核心将是 RandomGeneratorCores。
06-traffic-gen: HybridGenerator 构造函数
让我们开始查看代码!
确保您已打开以下文件。
materials/02-Using-gem5/03-running-in-gem5/06-traffic-gen/components/hybrid_generator.py
在右侧,您将看到 HybridGenerator 的构造函数。
当我们初始化 HybridGenerator(通过 def __init__)时,我们将使用右侧的值初始化 AbstractGenerator(通过 super() __init__)。
class HybridGenerator(AbstractGenerator):
def __init__(
self,
num_cores: int = 2,
duration: str = "1ms",
rate: str = "1GB/s",
block_size: int = 8,
min_addr: int = 0,
max_addr: int = 131072,
rd_perc: int = 100,
data_limit: int = 0,
) -> None:
if num_cores < 2:
raise ValueError("num_cores should be >= 2!")
super().__init__(
cores=self._create_cores(
num_cores=num_cores,
duration=duration,
rate=rate,
block_size=block_size,
min_addr=min_addr,
max_addr=max_addr,
rd_perc=rd_perc,
data_limit=data_limit,
)
)
06-traffic-gen: 设计 HybridGenerator
现在,我们的 HybridGenerator 类有一个构造函数,但我们需要返回一个核心列表。
在 gem5 中,返回核心列表的方法通常命名为 _create_cores。
如果您查看我们的文件 hybrid_generator.py,您会看到这个名为 _create_cores 的方法。
06-traffic-gen: HybridGenerator:初始化变量
让我们定义 _create_cores!
让我们首先声明/定义一些重要的变量。
首先,我们将声明我们的核心列表。
然后,我们将定义 LinearGeneratorCores 和 RandomGeneratorCores 的数量。
在标记为 (1) 的注释下添加以下行。
core_list = []
num_linear_cores = get_num_linear_cores(num_cores)
num_random_cores = num_cores - num_linear_cores
06-traffic-gen: HybridGenerator:划分内存地址范围
接下来,让我们为每个 LinearGeneratorCore 定义内存地址范围。
如果我们想给每个 LinearGeneratorCore 一个相等的给定内存地址范围块,我们需要将 min_addr 到 max_addr 的范围划分为 num_linear_cores 个片段。
为此,我们需要在标记为 (2) 的注释下向代码添加以下行。
addr_ranges = partition_range(min_addr, max_addr, num_linear_cores)
addr_ranges 将是一个从 min_addr 到 max_addr 的等长分区的 num_linear_cores 长度列表。
06-traffic-gen: 划分内存地址范围(续)
例如,我们有 min_addr=0、max_addr=32768 和 num_cores=16(8 个 LinearGeneratorCores),那么
addr_ranges=
[(0, 4096), (4096, 8192), (8192, 12288), (12288, 16384),
(16384, 20480), (20480, 24576), (24576, 28672), (28672, 32768)]
对于第 i 个 LinearGeneratorCore,我们取 addr_ranges 中的第 i 个条目。min_addr 是该条目的第一个值,max_addr 是该条目中的第二个值。
在此示例中,LinearGeneratorCore 0 使用 min_addr=0 和 max_addr=4096 初始化,LinearGeneratorCore 1 使用 min_addr=4096 和 max_addr=8192 初始化,依此类推。
06-traffic-gen: HybridGenerator:创建核心列表:LinearGeneratorCore
接下来,让我们开始创建我们的核心列表。
首先,让我们添加所有 LinearGeneratorCores。
在标记为 (3) 的注释下添加右侧的行。
for i in range(num_linear_cores):
core_list.append(LinearGeneratorCore(
duration=duration,
rate=rate,
block_size=block_size,
min_addr=addr_ranges[i][0],
max_addr=addr_ranges[i][1],
rd_perc=rd_perc,
data_limit=data_limit,)
)
06-traffic-gen: HybridGenerator:创建核心列表说明:LinearGeneratorCore
在 for 循环中,我们创建 num_linear_cores 个 LinearGeneratorCores,并将每个添加到我们的 core_list 中。
每个 LinearGeneratorCore 参数都使用构造函数中的相同值初始化,除了 min_addr 和 max_addr。
我们更改 min_addr 和 max_addr,以便每个 LinearGeneratorCore 只模拟对 HybridGenerator 的 min_addr 到 max_addr 范围的一部分的访问。
###
for i in range(num_linear_cores):
core_list.append(LinearGeneratorCore(
duration=duration,
rate=rate,
block_size=block_size,
min_addr=addr_ranges[i][0],
max_addr=addr_ranges[i][1],
rd_perc=rd_perc,
data_limit=data_limit,)
)
06-traffic-gen: HybridGenerator:创建核心列表:RandomGeneratorCore
现在我们已经添加了 LinearGeneratorCores,让我们添加所有 RandomGeneratorCores。
在标记为 (4) 的注释下添加右侧的行。
###
for i in range(num_random_cores):
core_list.append(RandomGeneratorCore(
duration=duration,
rate=rate,
block_size=block_size,
min_addr=min_addr,
max_addr=max_addr,
rd_perc=rd_perc,
data_limit=data_limit,)
)
06-traffic-gen: HybridGenerator:创建核心列表说明:RandomGeneratorCore
再次,在 for 循环中,我们创建 num_linear_cores 个 RandomGeneratorCores,并将每个添加到我们的 core_list 中。
每个 RandomGeneratorCore 参数都使用构造函数中的相同值初始化,包括 min_addr 和 max_addr。
min_addr 和 max_addr 不会改变,因为每个 RandomGeneratorCore 应该能够访问 HybridGenerator 的 min_addr 到 max_addr 的整个范围。
###
for i in range(num_random_cores):
core_list.append(RandomGeneratorCore(
duration=duration,
rate=rate,
block_size=block_size,
min_addr=min_addr,
max_addr=max_addr,
rd_perc=rd_perc,
data_limit=data_limit,)
)
06-traffic-gen: HybridGenerator:返回并开始配置
我们几乎完成了这个文件!
让我们通过在标记为 (5) 的注释下添加以下行来返回我们的 core_list。
return core_list
现在,打开文件 materials/02-Using-gem5/03-running-in-gem5/06-traffic-gen/simple-traffic-generators.py。
让我们用 HybridGenerator 替换我们的 LinearGenerator。
首先,在代码顶部的某个位置添加以下行以导入 HybridGenerator。
from components.hybrid_generator import HybridGenerator
06-traffic-gen: HybridGenerator:配置
在右侧的这段代码中,您当前应该有一个 LinearGenerator。
让我们用 HybridGenerator 替换它。
将以下行
generator = LinearGenerator(
num_cores=1
)
替换为
generator = HybridGenerator(
num_cores=6
)
###
cache_hierarchy = MyPrivateL1SharedL2CacheHierarchy()
memory = SingleChannelDDR3_1600()
generator = LinearGenerator(
num_cores=1
)
motherboard = TestBoard(
clk_freq="3GHz",
generator=generator,
memory=memory,
cache_hierarchy=cache_hierarchy,
)
06-traffic-gen: HybridGenerator:配置(续)
现在它应该如下所示。
###
cache_hierarchy = MyPrivateL1SharedL2CacheHierarchy()
memory = SingleChannelDDR3_1600()
generator = HybridGenerator(
num_cores=6
)
motherboard = TestBoard(
clk_freq="3GHz",
generator=generator,
memory=memory,
cache_hierarchy=cache_hierarchy,
)
06-traffic-gen: HybridGenerator:运行
现在,我们已经创建了一个 HybridGenerator,让我们再次运行程序!
确保您在以下目录中。
materials/02-Using-gem5/03-running-in-gem5/06-traffic-gen/
现在使用以下命令运行。
gem5 --debug-flags=TrafficGen --debug-end=1000000 \
simple-traffic-generators.py
06-traffic-gen: HybridGenerator:输出
运行命令后,您应该看到类似以下的内容。
7451: system.processor.cores5.generator: RandomGen::getNextPacket: r to addr 80a8, size 8
7451: system.processor.cores5.generator: Next event scheduled at 14902
7451: system.processor.cores4.generator: RandomGen::getNextPacket: r to addr 10a90, size 8
7451: system.processor.cores4.generator: Next event scheduled at 14902
7451: system.processor.cores3.generator: LinearGen::getNextPacket: r to addr 18000, size 8
7451: system.processor.cores3.generator: Next event scheduled at 14902
7451: system.processor.cores2.generator: LinearGen::getNextPacket: r to addr 10000, size 8
7451: system.processor.cores2.generator: Next event scheduled at 14902
7451: system.processor.cores1.generator: LinearGen::getNextPacket: r to addr 8000, size 8
7451: system.processor.cores1.generator: Next event scheduled at 14902
7451: system.processor.cores0.generator: LinearGen::getNextPacket: r to addr 0, size 8
7451: system.processor.cores0.generator: Next event scheduled at 14902
如您所见,核心 0、1、2 和 3 是 LinearGeneratorCores,核心 4 和 5 是 RandomGeneratorCores!
06-traffic-gen: HybridGenerator:统计信息
现在,让我们看看 LinearGeneratorCores 和 RandomGeneratorCores 之间的一些统计差异。
运行以下命令以查看每个核心的 l1 数据缓存的未命中率。
grep ReadReq.missRate::processor m5out/stats.txt
在下一张幻灯片中,您将看到预期的输出(为便于阅读,删除了一些文本)。
06-traffic-gen: HybridGenerator:统计信息(续)
system.cache_hierarchy.l1dcaches0.ReadReq.missRate::processor.cores0.generator 0.132345
system.cache_hierarchy.l1dcaches1.ReadReq.missRate::processor.cores1.generator 0.133418
system.cache_hierarchy.l1dcaches2.ReadReq.missRate::processor.cores2.generator 0.133641
system.cache_hierarchy.l1dcaches3.ReadReq.missRate::processor.cores3.generator 0.132971
system.cache_hierarchy.l1dcaches4.ReadReq.missRate::processor.cores4.generator 0.876426
system.cache_hierarchy.l1dcaches5.ReadReq.missRate::processor.cores5.generator 0.875055
核心 0、1、2 和 3(LinearGeneratorCores)的平均未命中率为 0.13309375(约 13.3%)。
核心 4 和 5(RandomGeneratorCores)的平均未命中率为 0.8757405(约 87.5%)。
这是因为 LinearGeneratorCores 线性访问内存。因此,它们表现出更多的局部性,这反过来导致 l1dcache 中的未命中更少。
另一方面,由于 RandomGeneratorCores 随机访问内存,缓存无法以相同的方式利用局部性。
总结
总的来说,我们讨论了两类流量生成器:Linear(线性)和 Random(随机)。
LinearGenerators 模拟线性内存访问,RandomGenerators 模拟随机内存访问。
我们研究了如何配置使用这些流量生成器的板。
我们还扩展了 AbstractGenerator 类以创建 HybridGenerator,它同时模拟线性和随机内存访问。
最后,我们看到了 LinearGeneratorCores 和 RandomGeneratorCores 之间的一些统计差异。